Introdução ao aprendizado de máquinas
O Aprendizado de Máquinas, uma linha de pesquisa dentro de Inteligência Artificial, tem como objetivo criar programas capazes de aprender uma determinada tarefa utilizando um conjunto de dados ou medida de desempenho.
Ao invés de criar um programa especificando os passos para executar sua tarefa, no aprendizado de máquinas utilizamos algoritmos que aprendem uma tarefa conforme seu treinamento. Aqui tem um vídeo do Marcelo Tas explicando o que é Aprendizado de Maquinas.
Modelo
Este algoritmo é treinando para aprender a executar uma tarefa, ele é conhecido como Modelo. Os modelos podem ser treinados para prever:
- Se um comentário é positivo, neutro ou negativo;
- Se uma compra no cartão de crédito é real ou fraude;
- Quais produtos podem ser oferecidos para um cliente com base no seu histórico de compras;
- Com base no histórico de sites acessados por um usuário, quais propagandas fará o usuário clicar e comprar o produto anunciado;
- Qual o próximo movimento que deve ser feito para aumentar as chances de vencer um jogo.
O treinamento dos modelos normalmente é feito utilizando uma das seguintes abordagens:
- Aprendizado supervisionado;
- Aprendizado não supervisionado;
- Aprendizado semi-supervisionado;
- Aprendizado por reforço.
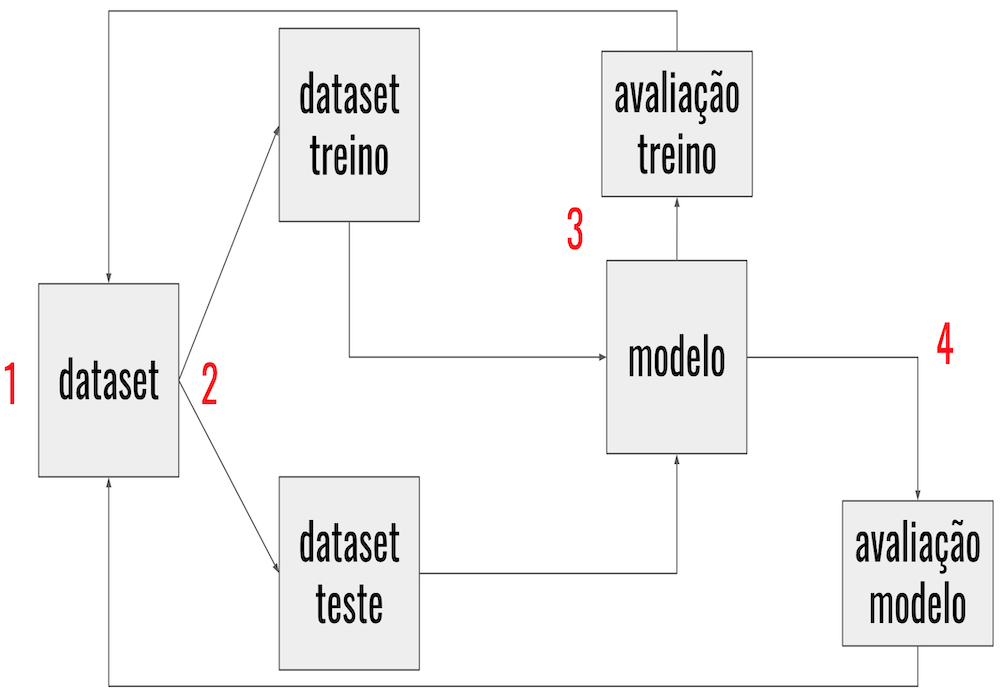
A Figura 1 apresenta um fluxo resumido de como funciona de modo geral o treinamento de um modelo:
Passo 1. Dado seu conjunto de dados (dataset) já coletado, a primeira parte que precisa ser análisada é quais caracteristicas (variáveis) devem ser utilizadas, aqui também ocorre um tratamento dos dados para padronizar o formato dos dados, preencher as informações que estão faltando, gerar novas caracteristicas a partir das caracteristicas iniciais, remover dados inválidos (ou outliers, normalmente informações que atrapalham o aprendizado do modelo), se houver um valor para a saída esperada (também conhecido como rotulo ou classe) padronizar esses valores (por exemplo: definir todas as saídas como númericas e em ordem crescente), etc;
Passo 2. O dataset é dividido normalmente em duas partes, uma parte (algo em torno de 70% a 80% do dataset) é usada para realizar o treino do modelo, a segunda parte (que o modelo não conheceu durante o treinamento) é usado para avaliar a tarefa que o modelo aprendeu;
Passo 3. A escolha do modelo (Decision Tree, kNN, Naive Bayes, SVM, Redes Neurais, etc) ocorrerá de acordo com o dataset e objetivo (classificação, regressão, agrupamento, etc). Nesse ponto ocorre o treinamento do modelo e normalmente fazemos uma avaliação cruzada com os dados de treino e se necessário voltamos ao Passo 1 para tentar melhorar as caracteristicas usadas no treino;
Passo 4. Depois que realizamos o treino e com os dados de treino obtemos um resultado satisfatório na tarefa que o modelo deve aprender, passamos para o passo de teste do modelo utilizando dados que são desconhecidos para o modelo, nesse ponto tentamos obter um resultado mais real de qual será o comportamento do modelo quando for disponibilizado em produção, se os resultados não forem satisfatório normalmente voltamos ao Passo 1 e começamos todo o processo novamente para obter uma acurácia melhor.
Figura 1: Aprendizado a partir dos dados.
Aprendizado supervisionado
Neste treinamento os dados (também conhecido como amostras ou exemplos) já estão rotulados, por tanto há informações sobre um exemplo e sua representação (rótulo / classe).
Utilizando um dataset, um modelo é treinado com o objetivo de reconhecer padrões nas características que melhor discriminam os rótulos de cada exemplo.
Após o treinamento é esperado que o modelo consiga reconhecer as características de um novo conjunto de dados e rotulá-los da melhor forma possível.
Quanto maior a variabilidade do dataset de treinamento, mais generalizado será o treinamento, podendo prever com mais acurácia novos conjuntos de dados.
Aqui tem um vídeo do canal Zurubabel explicando o que é Aprendizado supervisionado.
Aprendizado não supervisionado
No aprendizado não supervisionado o dataset não está rotulado, desta forma o aprendizado é realizado nos padrões identificados e alguma medida de avaliação que informa se está fazendo a tarefa da melhor maneira possível.
A tarefa mais comum é o agrupamento (clustering). Aqui tem um vídeo do canal Data Science Academy explicando o que é Aprendizado não supervisionado.
Aprendizado semi-supervisionado
No aprendizado semi-supervisionado uma parte do dataset está rotulado, por tanto tenta-se generalizar o treinamento da melhor maneira possível com os dados rotulados para tentar rotular os demais dados.
Aprendizado por reforço
O aprendizado por reforço possui um treinamento em que o modelo é avaliado a cada execução de sua tarefa e recebe um reforço positivo (quando a tarefa é feita igual ou similar ao esperado) ou reforço negativo (quando está fazendo algo de modo errado).
Aqui tem um vídeo do Guilherme de Lazari explicando o que é Aprendizado por reforço e apresentando alguns exemplos práticos.