Introdução ao Big Data
Introdução
Big Data está relacionado com a capacidade de gerar conhecimento legível ou por meio de modelo computacional, a partir de dados estruturados e não estruturados, e também utilizando mais dados do que é possível armazenar.
As principais tarefas estão relacionadas a classificação, agrupamento e regressão, que são implementados a partir do treinamento de modelos de aprendizado de máquinas.
O pipeline básico do Big Data segue o fluxo:
- Obter dados
- Separar os dados (teste e treino)
- Transformar os dados (filtrar atributos, normalizar valores, converter valores, etc)
- Treinar e avaliar os modelos de acordo com a tarefa necessária
- Otimizar o modelo escolhido
- Validar o modelo com novos valores
O Big Data atende a 4 V’s: Variedade (diversidade dos dados), Velocidade (captura e processamento), Volume (quantidade de dados) e Veracidade (relevância dos dados).
Os dados brutos são tantos, que é necessário distribuir o armazenamento em diversos servidores. E como fica a redundância dos dados? Será que ter muitos dados indica que a perda de uma parte influência ou não no restante? Como utilizar esses dados, processar tudo e esperar ou processar em partes e agrupar os resultados?
O dados são obtidos normalmente de forma contínua e precisam ser processados on-line para gerar conhecimento o mais rápido possível. Os algoritmos devem ser implementados para permitir processar todos os dados de forma distribuída e ao termino (parcial ou final) conseguir combinar todos os resultados para gerar os resultados da sua tarefa.
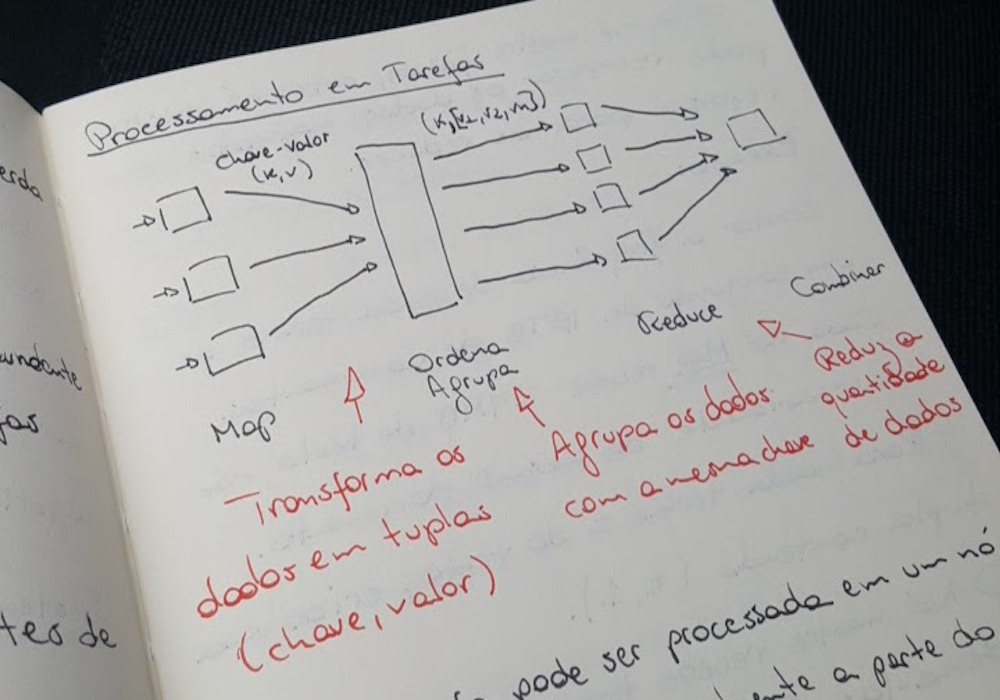
MapReduce
O MapReduce é uma forma de trabalhar com grandes quantidades de dados distribuídos sem alterar o resultado do algoritmo. No qual o map faz o mapeamento dos dados (muitas vezes relacionados a transformações) e o reduce reduz a quantidade de dados.
Mas mapear e reduzir gera o que? Esse é o ponto principal, dado a tarefa que deve ser executada, o objetivo é como aplicar o MapReduce para executar essa tarefa.
Os sistemas de arquivos distribuídos (HDFS, GFS, CloudStore, etc) tendem a armazenar as informações em partes de 64MB replicados em pelo menos três servidores em hacks diferentes para evitar falhas. A localização de cada parte dos dados é de conhecimento do Nó Mestre que também é replicado para evitar falhas.
Quando aplicamos MapReduce nesses sistemas de arquivos distribuídos: o map tende a mapear os dados nos nós que contêm cada parte dos dados e depois seus resultados são agrupados no Nó Mestre, que divide novamente os dados entre os nós para realizar o reduce e por fim combinar gerando o resultado de saída do algoritmo.
Nessa situação se ocorrer falha em algum dos nós, basta esperar que o outro nó devolva o resultado, pois todas as operações são realizadas de modo distribuído em mais de um servidor diferente, evitando assim possíveis falhas.