Entendendo a diferença entre Acurácia, Precisão e Revocação

Quando montamos uma matriz de confusão, podemos verificar na diagonal principal se estamos associando as amostras corretamente com seus rótulos, mas vamos olhar de maneira mais geral para todos valores apresentados nessa matriz.
Neste exemplo, temos uma matriz de confusão gerada a partir de um classificador de textos, que indica se um texto é um spam ou não é spam (ham).
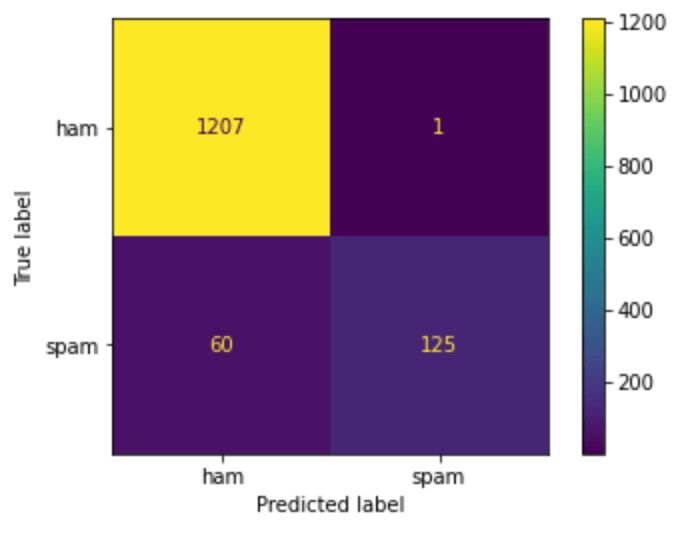
Essa matriz pode ser dividida em 4 partes:
No canto superior esquerdo temos o True Positive (TP), no exemplo são os textos verdadeiros (não são spam) e que foram classificados corretamente como textos verdadeiros.
No canto superior direito temos o False Negative (FN), no exemplo são os textos verdadeiros, mas que foram classificados de modo errado como spam.
No canto inferior esquerdo temos o False Positive (FP), no exemplo são os textos que são spam, mas foram classificados como textos verdadeiros.
No canto inferior direito temos o True Negative (TN), no exemplo são os textos de spam que foram classificados corretamente como spam.
Então, olhando para a primeira linha da matriz, podemos entender que das 1208 amostras ham (que não são spam), classificou corretamente 1207 e errou apenas 1, isso é bom porque ninguém quer suas mensagens reais sendo classificadas como spam; e para as 185 amostras de spam classificou corretamente 125 e errou 60, isso é aceitável e ainda vamos receber alguns spams, mas dá margem para melhorar.
Agora que conhecemos a matriz de confusão vamos entender três métricas que podemos obter dela: Acurácia, Precisão e Revocação.
Acurácia (Accuracy)
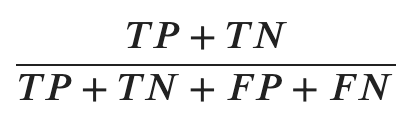
Na acurácia, somamos a quantidade de amostras classificadas corretamente, tanto com a classe positiva como com a classe negativa, e dividimos pelo total de amostras.
O resultado deste cálculo indica o percentual das amostras que foram rotuladas corretamente, quanto maior este valor, mais amostras foram classificadas corretamente.
Note que o TP + TN representa a diagonal principal, por isso que quando olhamos para a matriz de confusão é muito importante que os valores da diagonal principal sejam maiores que os demais valores.
No Python podemos usar o Scikit-Learn para calcular a acurácia, só precisamos informar quais são os rótulos corretos e quais os rótulos que foram preditos:
1
2
from sklearn.metrics import accuracy_score
accuracy_score(y, y_predito)
Precisão (Precision)
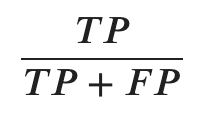
A precisão usa o total de amostras classificadas positivamente e divide pelo total de amostras de rótulos positivo, aqui incluindo também os falsos positivos.
Note que TP + FP representam a primeira coluna da matriz de confusão.
Esse valor indica o percentual entre todas as amostras que estão sendo classificadas de forma positiva e que realmente são corretas, então quanto maior for este percentual menor será o número de amostras classificadas como falsos positivos.
No Python podemos usar o Scikit-Learn para calcular a precisão, só precisamos informar quais são os rótulos corretos e quais os rótulos que foram preditos:
1
2
from sklearn.metrics import precision_score
precision_score(y, y_predito)
Revocação (Recall)
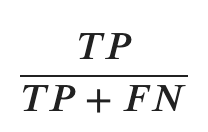
A revocação leva em consideração o total de amostras classificadas positivamente e divide pelo total de amostras que deveriam ser da classe positiva que são as amostras positivas mais os falsos negativos.
Note que TP + FN representam a primeira linha da matriz de confusão.
Esse valor indica o percentual de todas as amostras positivas que realmente foram classificadas de forma positiva.
No Python podemos usar o Scikit-Learn para calcular a precisão, só precisamos informar quais são os rótulos corretos e quais os rótulos que foram preditos:
1
2
from sklearn.metrics import recall_score
recall_score(y, y_predito)