Tag ia
Continuing the last post I'm trying to improve the random agent to obtain a best score.
In this post I explain how create a agent that execute a shot in a random object in the screen, and save in a file (to future use) the shots...
This post explain how to identify in Angry Birds the pigs and execute a shot.
This post explain how to configure and start to create an intelligent agent to play Angry Birds.
Tag angrybirds
Continuing the last post I'm trying to improve the random agent to obtain a best score.
In this post I explain how create a agent that execute a shot in a random object in the screen, and save in a file (to future use) the shots...
This post explain how to identify in Angry Birds the pigs and execute a shot.
This post explain how to configure and start to create an intelligent agent to play Angry Birds.
Tag java
Continuing the last post I'm trying to improve the random agent to obtain a best score.
In this post I explain how create a agent that execute a shot in a random object in the screen, and save in a file (to future use) the shots...
This post explain how to identify in Angry Birds the pigs and execute a shot.
This post explain how to configure and start to create an intelligent agent to play Angry Birds.
Tag random
Continuing the last post I'm trying to improve the random agent to obtain a best score.
In this post I explain how create a agent that execute a shot in a random object in the screen, and save in a file (to future use) the shots...
Tag big data
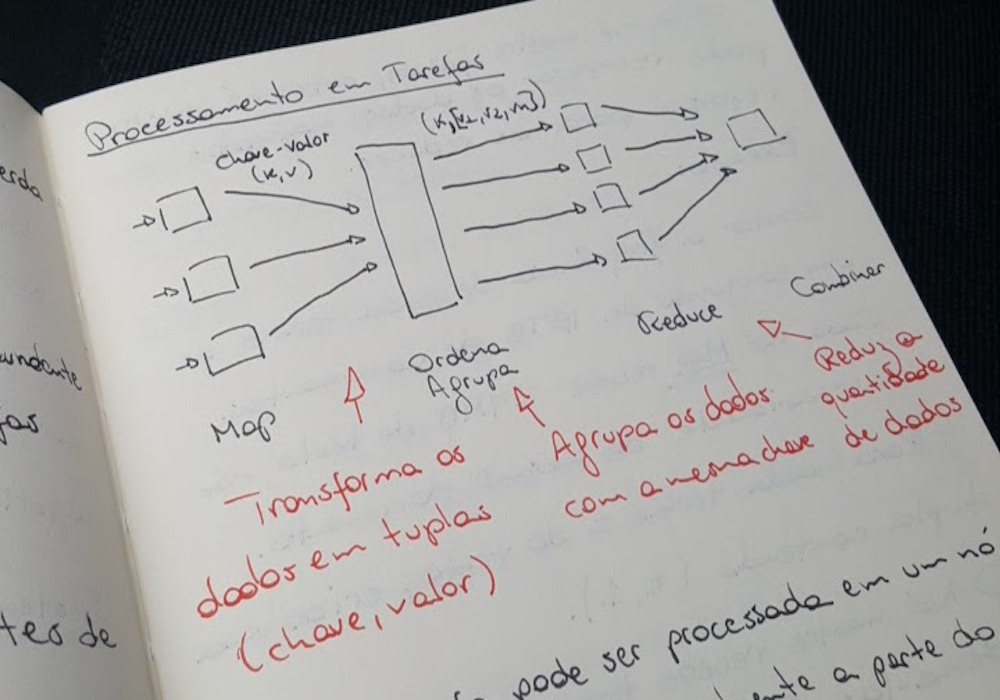
Uma breve introdução ao uso de Big Data com seu pipeline básico, e também a ideia de como o MapReduce é usado para tratar a distribuição dos dados.
Tag mapreduce
Neste capítulo o autor aborda sobre como o dado é transformado entre as camadas da aplicação, os diversos tipos de banco de dados e linguagens para consultar os dados.
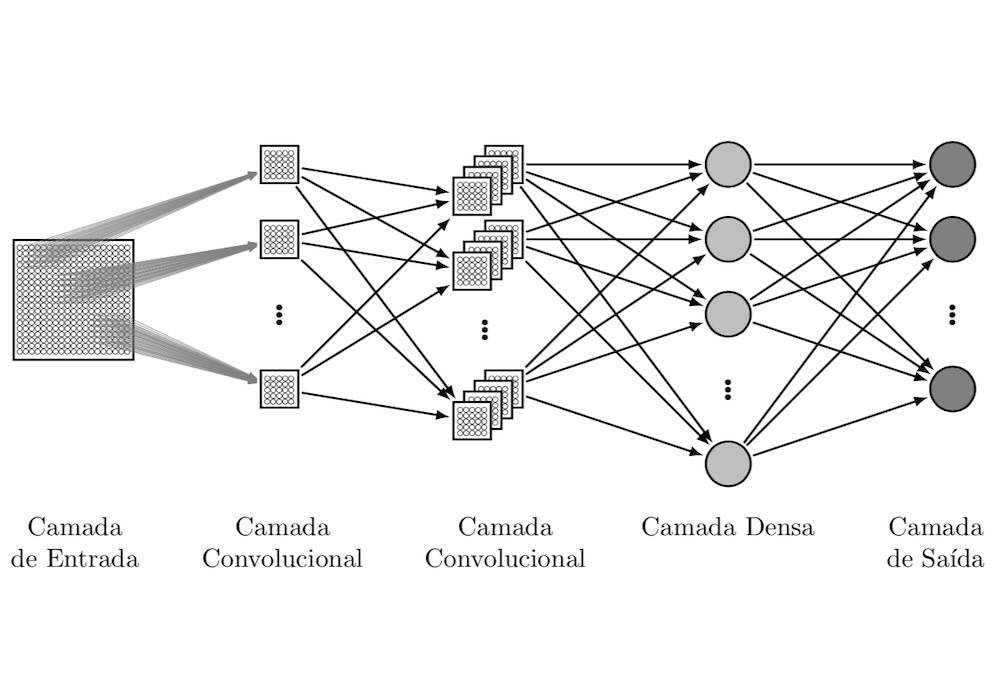
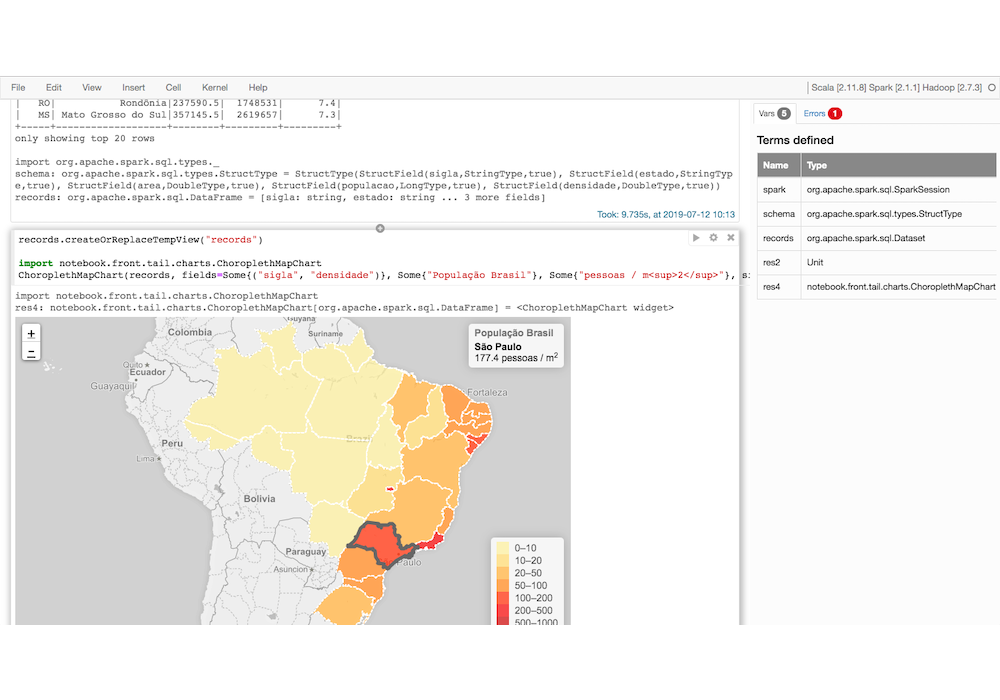
Neste documento é apresentado um exemplo de problema que pode ser tratado por meio de Redes Neurais Convolucionais sendo implementado utilizando a técnica de MapReduce do Spark.
Uma breve introdução ao uso de Big Data com seu pipeline básico, e também a ideia de como o MapReduce é usado para tratar a distribuição dos dados.
Tag mineração de dados
Este post apresenta um relatório sobre os passos utilizados na resolução do projeto de predição de doenças utilizando Microarrays disponível no KDnuggets.
Tag classificação
Vejamos como funciona a Máquina de Vetores de Suporte (SVM) e como podemos usá-la para treinar um modelo que classifica dígitos que foram escritos manualmente.
Veja neste post como usar a Regressão Lógistica e também como podemos usar uma regressão para fazer a tarefa de classificação, neste exemplo vamos classificar textos de SMS como Spam...
Veja como usar Naive Bayes e calcular as probabilidades das características para realizar uma tarefa de classificação.
Tudo pode ser classificado e rotulado, mas porque queremos classificar textos ou como isso poderia ajudar o negócio da empresa que trabalho?
KNN é um algoritmo que permite classificar novas amostras a partir da distância em relação às demais amostras do dataset. Veja nesse artigo como funciona o KNN.
Este post explica como funciona o treinamento de uma Decision Tree (Árvore de Decisão) com o objetivo de aprender classificação de dados e como utilizar sua implementação feita no scikit-learn....
Este post apresenta um relatório sobre os passos utilizados na resolução do projeto de predição de doenças utilizando Microarrays disponível no KDnuggets.
Tag microarray
Este post apresenta um relatório sobre os passos utilizados na resolução do projeto de predição de doenças utilizando Microarrays disponível no KDnuggets.
Tag convolutional neural networks
Neste documento é apresentado um exemplo de problema que pode ser tratado por meio de Redes Neurais Convolucionais sendo implementado utilizando a técnica de MapReduce do Spark.
Tag spark
Já comentei sobre Regressão Linear Simples e Múltipla, e agora veremos como implementar em Scala usando a biblioteca MLLib do Apache Spark.
Notebooks help data scientists to explore datasets and has became one of the main tools used in Data Science, but they also add some challenges like how to deploy in...
Neste documento é apresentado um exemplo de problema que pode ser tratado por meio de Redes Neurais Convolucionais sendo implementado utilizando a técnica de MapReduce do Spark.
Tag machine learning
Já comentei sobre Regressão Linear Simples e Múltipla, e agora veremos como implementar em Scala usando a biblioteca MLLib do Apache Spark.
Vejamos como funciona a Máquina de Vetores de Suporte (SVM) e como podemos usá-la para treinar um modelo que classifica dígitos que foram escritos manualmente.
A partir da Matriz de Confusão conseguimos obter as métricas Acurácia, Precisão e Revocação para entender melhor como está o modelo.
Veja neste post como usar a Regressão Lógistica e também como podemos usar uma regressão para fazer a tarefa de classificação, neste exemplo vamos classificar textos de SMS como Spam...
Muitas vezes uma função de 1º grau que gera reta não é bom o bastante para ser usada na regressão, nesse caso podemos usar funções polinomiais para ajudar predição dos...
Veja neste post como usar o k-Means para realizar a tarefa de agrupamento de dados.
Veja como usar Naive Bayes e calcular as probabilidades das características para realizar uma tarefa de classificação.
Tudo pode ser classificado e rotulado, mas porque queremos classificar textos ou como isso poderia ajudar o negócio da empresa que trabalho?
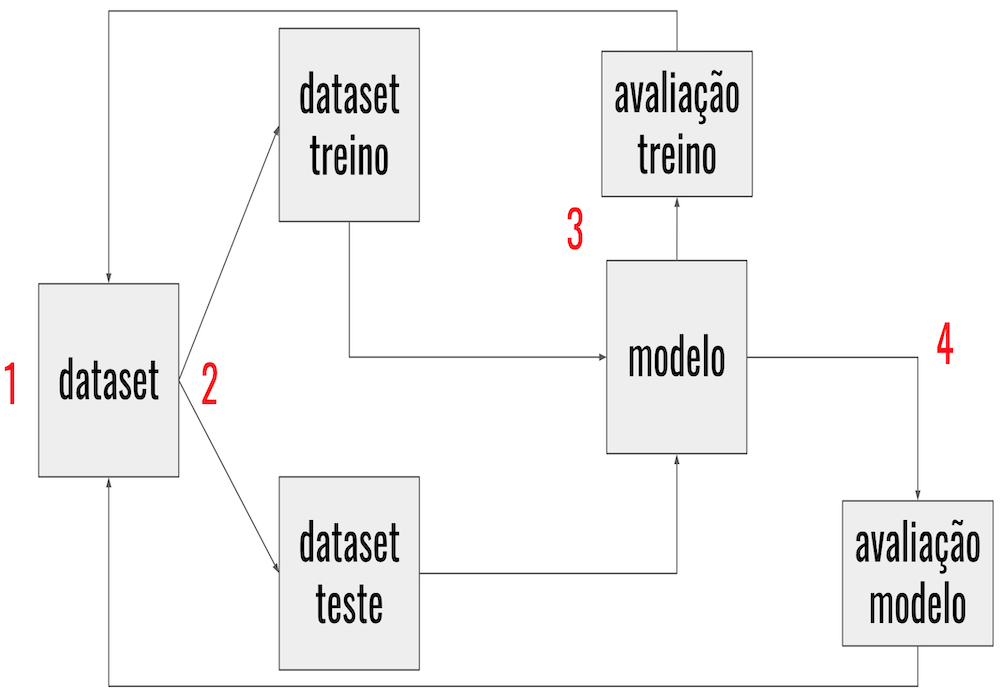
Introdução do que é aprendizado de máquinas, modelos e abordagens de treinamento.
Tag supervisionado
Introdução do que é aprendizado de máquinas, modelos e abordagens de treinamento.
Tag não supervisionado
Introdução do que é aprendizado de máquinas, modelos e abordagens de treinamento.
Tag reforço
Introdução do que é aprendizado de máquinas, modelos e abordagens de treinamento.
Tag aprendizado supervisionado
Este post explica como funciona o treinamento de uma Decision Tree (Árvore de Decisão) com o objetivo de aprender classificação de dados e como utilizar sua implementação feita no scikit-learn....
Tag entropia
Este post explica como funciona o treinamento de uma Decision Tree (Árvore de Decisão) com o objetivo de aprender classificação de dados e como utilizar sua implementação feita no scikit-learn....
Tag decision tree
Este post explica como funciona o treinamento de uma Decision Tree (Árvore de Decisão) com o objetivo de aprender classificação de dados e como utilizar sua implementação feita no scikit-learn....
Tag iris
Este post explica como funciona o treinamento de uma Decision Tree (Árvore de Decisão) com o objetivo de aprender classificação de dados e como utilizar sua implementação feita no scikit-learn....
Tag numpy
Veja uma revisão de alguns conceitos importantes de Estatística e Probabilidade e como usar em Python com a biblioteca NumPy.
Review some basic concepts of Linear Algebra, and how to calculate using Python with NumPy.
Veja uma revisão de alguns conceitos importantes de Álgebra Linear e como usar em Python com a biblioteca NumPy.
Tag vetores
Veja uma revisão de alguns conceitos importantes de Álgebra Linear e como usar em Python com a biblioteca NumPy.
Tag matriz
Veja uma revisão de alguns conceitos importantes de Álgebra Linear e como usar em Python com a biblioteca NumPy.
Tag distancia
Veja uma revisão de alguns conceitos importantes de Álgebra Linear e como usar em Python com a biblioteca NumPy.
Tag euclidiana
Veja uma revisão de alguns conceitos importantes de Álgebra Linear e como usar em Python com a biblioteca NumPy.
Tag vector
Review some basic concepts of Linear Algebra, and how to calculate using Python with NumPy.
Tag matrix
Review some basic concepts of Linear Algebra, and how to calculate using Python with NumPy.
Tag distance
Review some basic concepts of Linear Algebra, and how to calculate using Python with NumPy.
Tag euclidian
Review some basic concepts of Linear Algebra, and how to calculate using Python with NumPy.
Tag estatística
Veja uma revisão de alguns conceitos importantes de Estatística e Probabilidade e como usar em Python com a biblioteca NumPy.
Tag probabilidade
Veja uma revisão de alguns conceitos importantes de Estatística e Probabilidade e como usar em Python com a biblioteca NumPy.
Tag knn
KNN é um algoritmo que permite classificar novas amostras a partir da distância em relação às demais amostras do dataset. Veja nesse artigo como funciona o KNN.
Tag regressao linear
O que acha de tentar prever quanto será o lucro da empresa com base no investimento de marketing, ou quanto custa um apartamento com base na sua metragem, esse são...
Tag regressão linear
Há situações nas quais queremos utilizar mais de duas variáveis para realizar uma predição mais precisa e neste caso podemos utilizar a Regressão Linear Múltipla.
Tag inteligencia artificial
Vejamos como funciona a Máquina de Vetores de Suporte (SVM) e como podemos usá-la para treinar um modelo que classifica dígitos que foram escritos manualmente.
A partir da Matriz de Confusão conseguimos obter as métricas Acurácia, Precisão e Revocação para entender melhor como está o modelo.
Veja neste post como usar a Regressão Lógistica e também como podemos usar uma regressão para fazer a tarefa de classificação, neste exemplo vamos classificar textos de SMS como Spam...
Muitas vezes uma função de 1º grau que gera reta não é bom o bastante para ser usada na regressão, nesse caso podemos usar funções polinomiais para ajudar predição dos...
Veja neste post como usar o k-Means para realizar a tarefa de agrupamento de dados.
Veja como usar Naive Bayes e calcular as probabilidades das características para realizar uma tarefa de classificação.
Tudo pode ser classificado e rotulado, mas porque queremos classificar textos ou como isso poderia ajudar o negócio da empresa que trabalho?
Tag classificação de textos
Tudo pode ser classificado e rotulado, mas porque queremos classificar textos ou como isso poderia ajudar o negócio da empresa que trabalho?
Tag naive bayes
Veja como usar Naive Bayes e calcular as probabilidades das características para realizar uma tarefa de classificação.
Tag agrupamento
Veja neste post como usar o k-Means para realizar a tarefa de agrupamento de dados.
Tag k-means
Veja neste post como usar o k-Means para realizar a tarefa de agrupamento de dados.
Tag regressão polinomial
Muitas vezes uma função de 1º grau que gera reta não é bom o bastante para ser usada na regressão, nesse caso podemos usar funções polinomiais para ajudar predição dos...
Tag regressão logística
Veja neste post como usar a Regressão Lógistica e também como podemos usar uma regressão para fazer a tarefa de classificação, neste exemplo vamos classificar textos de SMS como Spam...
Tag metricas
A partir da Matriz de Confusão conseguimos obter as métricas Acurácia, Precisão e Revocação para entender melhor como está o modelo.
Tag svm
Vejamos como funciona a Máquina de Vetores de Suporte (SVM) e como podemos usá-la para treinar um modelo que classifica dígitos que foram escritos manualmente.
Tag scikit-learn
Vejamos como funciona a Máquina de Vetores de Suporte (SVM) e como podemos usá-la para treinar um modelo que classifica dígitos que foram escritos manualmente.
Tag regressão
Já comentei sobre Regressão Linear Simples e Múltipla, e agora veremos como implementar em Scala usando a biblioteca MLLib do Apache Spark.
Tag livro
Neste capítulo o autor aborda o conceito de particionamento na qual temos grandes volumes de dados que serão divididos de tal forma que cada registro pertence a apenas uma partição,...
Neste capítulo o autor aborda o conceito de replicação dos dados que está relacionado com a forma como disponibilizamos o mesmo dado em mais de uma máquina a fim de...
Neste capítulo o autor aborda o conceito de códificação e como o formato que salvamos os dados em disco influência para ler, escrever e também o espaço de armazenamento em...
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Neste capítulo o autor aborda sobre como o dado é transformado entre as camadas da aplicação, os diversos tipos de banco de dados e linguagens para consultar os dados.
Este primeiro capítulo o autor aborda três grandes pilares relacionados ao desenvolvimento de aplicações (disponibilidade, escalabilidade e manutenibilidade).
Resumo comentado dos capítulos do livro Designing Data-Intensive Applications do Martin Keplemmann.
Tag dados distribuídos
Resumo comentado dos capítulos do livro Designing Data-Intensive Applications do Martin Keplemmann.
Tag replicação de dados
Resumo comentado dos capítulos do livro Designing Data-Intensive Applications do Martin Keplemmann.
Tag particionamento de dados
Resumo comentado dos capítulos do livro Designing Data-Intensive Applications do Martin Keplemmann.
Tag processamento batch
Resumo comentado dos capítulos do livro Designing Data-Intensive Applications do Martin Keplemmann.
Tag processamento stream
Resumo comentado dos capítulos do livro Designing Data-Intensive Applications do Martin Keplemmann.
Tag desenvolvimento de aplicações
Este primeiro capítulo o autor aborda três grandes pilares relacionados ao desenvolvimento de aplicações (disponibilidade, escalabilidade e manutenibilidade).
Tag disponibilidade
Este primeiro capítulo o autor aborda três grandes pilares relacionados ao desenvolvimento de aplicações (disponibilidade, escalabilidade e manutenibilidade).
Tag escalabilidade
Este primeiro capítulo o autor aborda três grandes pilares relacionados ao desenvolvimento de aplicações (disponibilidade, escalabilidade e manutenibilidade).
Tag manutenibilidade
Este primeiro capítulo o autor aborda três grandes pilares relacionados ao desenvolvimento de aplicações (disponibilidade, escalabilidade e manutenibilidade).
Tag modelo de dados
Neste capítulo o autor aborda sobre como o dado é transformado entre as camadas da aplicação, os diversos tipos de banco de dados e linguagens para consultar os dados.
Tag sql
Neste capítulo o autor aborda sobre como o dado é transformado entre as camadas da aplicação, os diversos tipos de banco de dados e linguagens para consultar os dados.
Tag nosql
Neste capítulo o autor aborda sobre como o dado é transformado entre as camadas da aplicação, os diversos tipos de banco de dados e linguagens para consultar os dados.
Tag grafo
Neste capítulo o autor aborda sobre como o dado é transformado entre as camadas da aplicação, os diversos tipos de banco de dados e linguagens para consultar os dados.
Tag estrutura de dados
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag hash index
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag LSM-Tree
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag SSTable
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag OLAP
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag OLTP
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag armazenamento orientado a coluna
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag materialized view
Neste capítulo o autor aborda como os dados são armazenados e recuperados, como construir um index para melhorar a recuperação das informação, diferença entre OLAP e OLTP, armazenamento orientado a...
Tag encoding dos dados
Neste capítulo o autor aborda o conceito de códificação e como o formato que salvamos os dados em disco influência para ler, escrever e também o espaço de armazenamento em...
Tag evolução do schema
Neste capítulo o autor aborda o conceito de códificação e como o formato que salvamos os dados em disco influência para ler, escrever e também o espaço de armazenamento em...
Neste capítulo o autor aborda o conceito de códificação e como o formato que salvamos os dados em disco influência para ler, escrever e também o espaço de armazenamento em...
Tag replicação
Neste capítulo o autor aborda o conceito de replicação dos dados que está relacionado com a forma como disponibilizamos o mesmo dado em mais de uma máquina a fim de...
Tag disponibilidade dos dados
Neste capítulo o autor aborda o conceito de replicação dos dados que está relacionado com a forma como disponibilizamos o mesmo dado em mais de uma máquina a fim de...
Tag particionamento
Neste capítulo o autor aborda o conceito de particionamento na qual temos grandes volumes de dados que serão divididos de tal forma que cada registro pertence a apenas uma partição,...
Tag otimização de leitura e escrita
Neste capítulo o autor aborda o conceito de particionamento na qual temos grandes volumes de dados que serão divididos de tal forma que cada registro pertence a apenas uma partição,...














![Resumo do livro Designing Data-Intensive Applications [Em construção]](/assets/images/posts/2024-02-01-resumo-data-intensive.png)