Agrupando dados com o k-Means

Há tarefas de reconhecimento de padrões nas quais queremos agrupar nossos dados, mas não temos os rótulos ou classes previamente definidas no dataset, neste cenário podemos usar técnicas de aprendizado de máquinas não supervisionado.
Exemplo: dado um conjunto de dados composto pelas características x1 e x2, apresentadas na figura a seguir, como podemos agrupar estes dados?
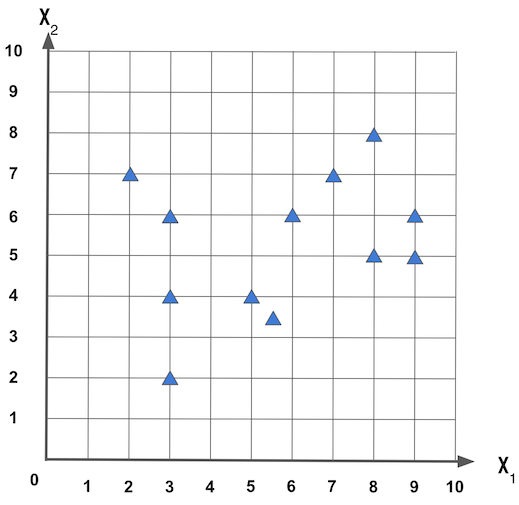
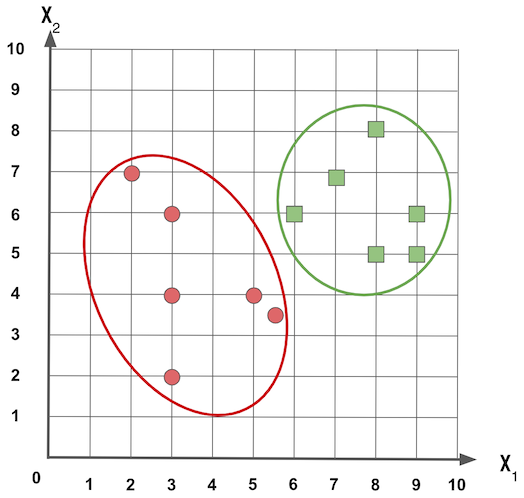
Se queremos dois grupos, podemos agrupar como:
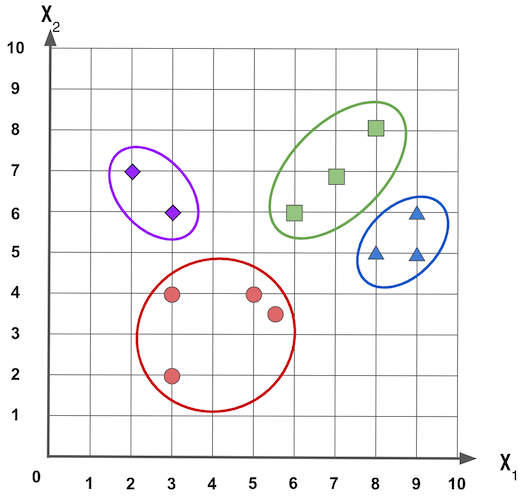
Se queremos ter quatro grupos, podemos ter algo como:
Mas aí começam as dúvidas, porque queremos agrupar os dados? Quantos grupos queremos? Será que a forma como esses dados estão agrupados faz sentido?
Agrupando os dados
O agrupamento de dados é usado quando temos características nas amostras que são similares e queremos agrupar as amostras com bases nessas similaridades.
Por exemplo: podemos agrupar pessoas com interesses similares para fazer uma campanha publicitária, agrupar reclamações que são documentos por palavras similares, imagens com características similares para encontrar fungos em plantações.
A quantidade de grupos que queremos formar vai variar de acordo com as características e o escopo dos dados. Se vamos agrupar reclamações provavelmente já temos um conjunto inicial de assuntos para endereçar as reclamações; se vamos fazer uma campanha publicitária podemos ter os grupos de pessoas que queremos apresentar o anúncio; etc.
Mas às vezes queremos que os dados nos deem uma dica de como eles podem ser agrupados, e para isso podemos usar técnicas de aprendizado de máquinas não supervisionado, um dos modelos que faz isso é o k-Means.
k-Means
A ideia do k-Means é encontrar k grupos com base na média das similaridades entre as características. No k-Means informamos o k que representa quantos grupos queremos, mas logo mais apresento como os dados podem sugerir quantos grupos podem ser uma boa escolha.
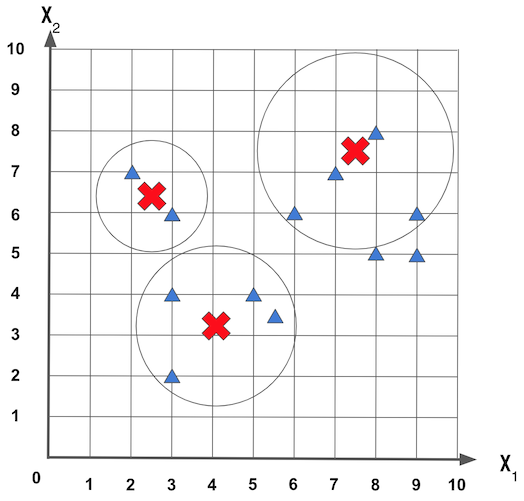
Para começar o k-Means vai escolher aleatoriamente as posições centrais dos k grupos. Usando o exemplo de conjunto de dados composto das características x1 e x2, e usando um k = 3, podemos ter inicialmente grupos criados de modo aleatório como mostrado na figura a seguir:
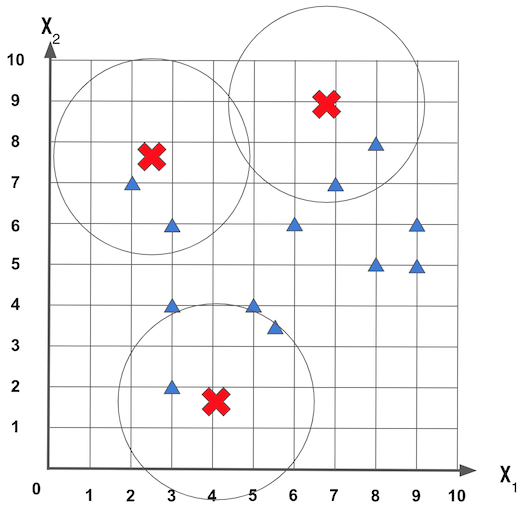
Agora o k-Means vai definir o grupo de cada amostra com relação a distância entre amostra e o centro do grupo, depois vai verificar se centroídes (os pontos centrais de cada grupo) estão realmente no centro de cada grupo, isso é feito calculando a média das distâncias entre todos as amostras que estão dentro do grupo.
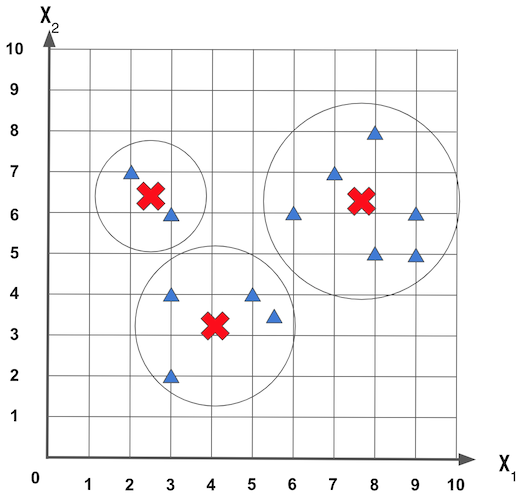
Se o valor calculado da posição central das amostras for diferente da centróide do grupo, há uma mudança da centróide do grupo para a nova posição do centro. A figura a seguir mostra um exemplo do ajuste dos centros que inicialmente estavam colocados de modo aleatório:
Com essa mudança do centro novas amostras podem entrar ou sair de um grupo. Este ajuste também vai servir para agrupar os dados que estão mais próximos, e isso indica que os dados possuem uma similaridade, a próxima figura mostra um novo ajuste nos dados:
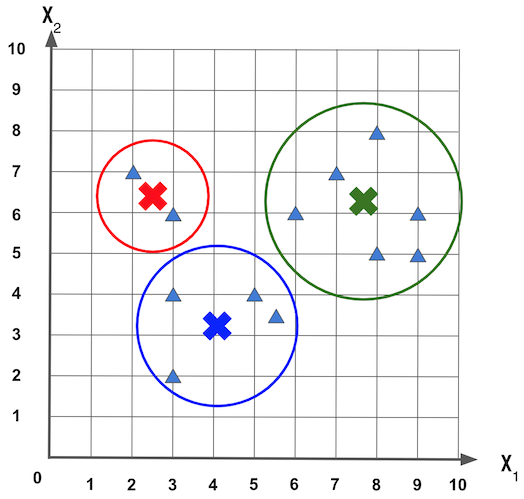
Este ajuste da posição central de cada grupo pode ocorrer por N iterações ou até que o centro dos grupos não altere mais. A figura a seguir mostra a posição final dos três grupos:
Exemplo: Agrupando as Flores Iris
Vamos fazer um novo exemplo usando o Iris Dataset que é composto por cinco características: SepalLength (Comprimento da Sépala), SepalWidth (Largura da Sépala), PetalLength (Comprimento da Pétala), PetalWidth (Largura da Pétala) e Class (Classe).
Existem três classes Versicolor, Setosa e Virginica, e com base nas características da flor queremos agrupar e definir a qual classe ela pertence.
Para carregar os dados das flores Iris no Python, vou usar o Pandas para ajudar. Neste código importei o Pandas, informei o nome das características do dataset (porque esse arquivo não tem cabeçalho), li o arquivo iris.data e mostrei as primeiras linhas do arquivo:
1
2
3
4
5
import pandas as pd
atributos = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Class']
df = pd.read_csv('iris.data', names=atributos)
df.head()
Vamos montar um ScatterPlot para ver como estão distribuídas as amostras das Flores de Iris, aqui vou usar apenas informações de comprimento e largura das petalas:
1
2
3
import seaborn as sns
sns.set(rc = {'figure.figsize':(15, 6)})
sns.scatterplot(data=df, x='PetalLength', y='PetalWidth', hue='Class');
Como no dataset já sabemos o rótulo dos dados, podemos visualizar como os dados estão dispersos nestes dois eixos, vemos claramente um grupo das Iris-Setosa, e o grupo da Iris-versicolor e Iris-virginica tem uma parte que se mistura, mas são grupos fáceis de visualizar, como mostrado a seguir:
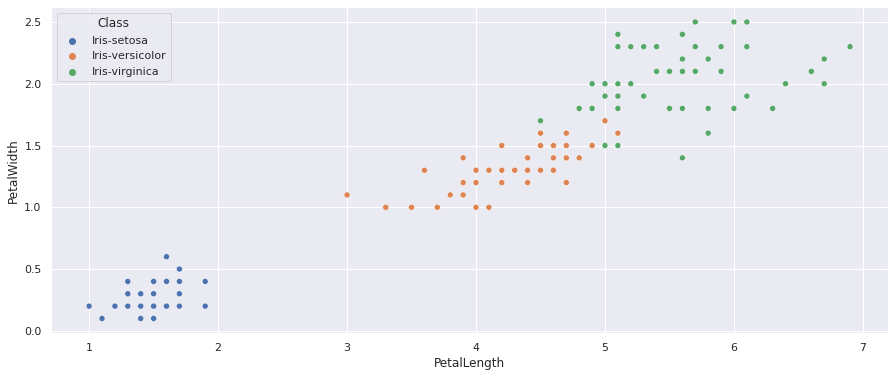
Mas e se fizermos o ScatterPlot sem a coluna que representa as classes das amostras:
1
sns.scatterplot(data=df, x='PetalLength', y='PetalWidth');
Teremos uma dispersão como mostrado na figura a seguir, no qual temos um grupo no canto inferior esquerdo e outro grande grupo no lado central e superior direito:
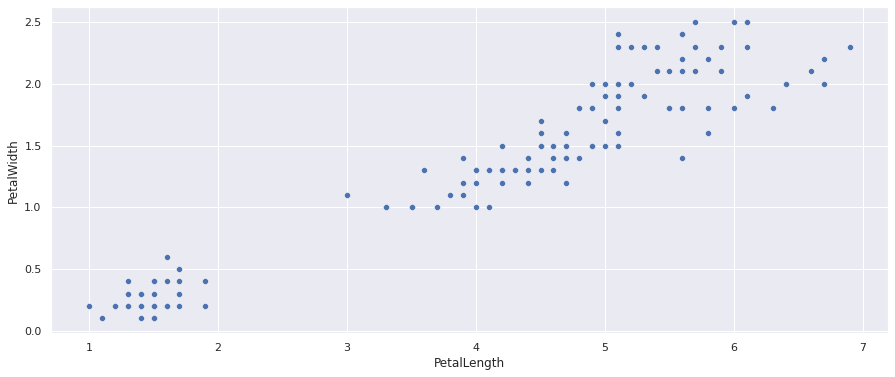
Agora sem saber as classificação de cada amostra fica mais difícil saber se o conjunto do grupo central e superior direito é apenas um grupo. Sabemos que são dois grupos, porque vimos no gráfico anterior, mas este pode ser o caso em que você não sabe ao certo quantos grupos tem.
Vamos criar uma matriz X com as características: SepalLength, SepalWidth, PetalLength e PetalWidth:
1
2
3
4
5
# Definimos uma matriz "X" com as caracteristicas que representam uma flor Iris.
X = df[df.columns.difference(['Class'])].values
print("Exemplo de caracteristicas da flor: {}".format(X[0]))
#Exemplo de caracteristicas da flor: [1.4 0.2 5.1 3.5]
Treinando o modelo de k-Means para agrupar as Flores de Iris
No Scikit Learn temos uma implementação do k-Means, vamos usar essa implementação para criar os grupos das Flores de Iris.
Vamos começar criando um modelo do k-Means e treinando ele com as características das flores:
1
2
3
4
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters = 3)
kmeans.fit(X)
A implementação padrão do k-Means usa um algoritmo de alocação inicial dos grupos chamado k-means++, que ao invés de escolher aleatoriamente a posição inicial de cada grupo, e correr o risco de ter grupos que aleatoriamente estão pertos um do outro, o k-means++ é uma versão mais inteligente que otimiza a convergência dos grupos.
Depois que o modelo do k-Means é treinado podemos obter as posições centrais dos grupos:
1
kmeans.cluster_centers_
Neste exemplo, os centróides dos grupos ficaram em:
1
2
3
array([[4.39354839, 1.43387097, 5.9016129 , 2.7483871 ],
[1.464 , 0.244 , 5.006 , 3.418 ],
[5.74210526, 2.07105263, 6.85 , 3.07368421]])
Também podemos ver os rótulos que foram atribuídos a cada amostra:
1
2
df['cluster'] = kmeans.labels_
df.head()
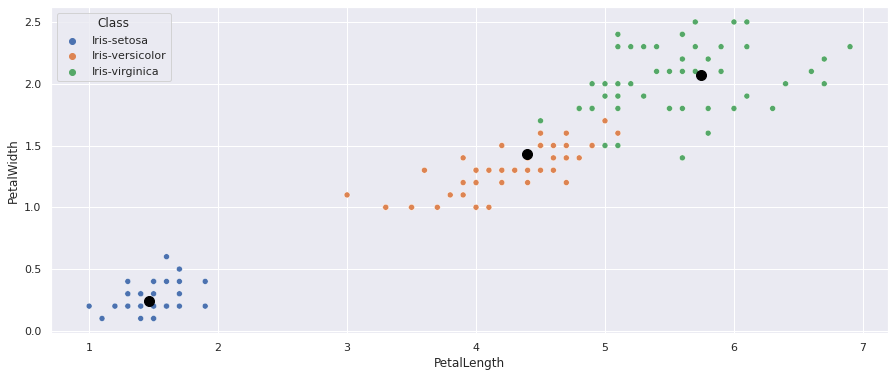
Vamos ver no ScatterPlot como estão a dispersão dos dados usando apenas a altura e comprimento das pétalas e também onde estão os três centróides que o k-Means identificou:
1
2
3
4
import matplotlib.pyplot as plt
sns.scatterplot(data=df, x='PetalLength', y='PetalWidth', hue='Class');
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=100, c='black');
Note como faz sentido o local onde estão os três centróides:
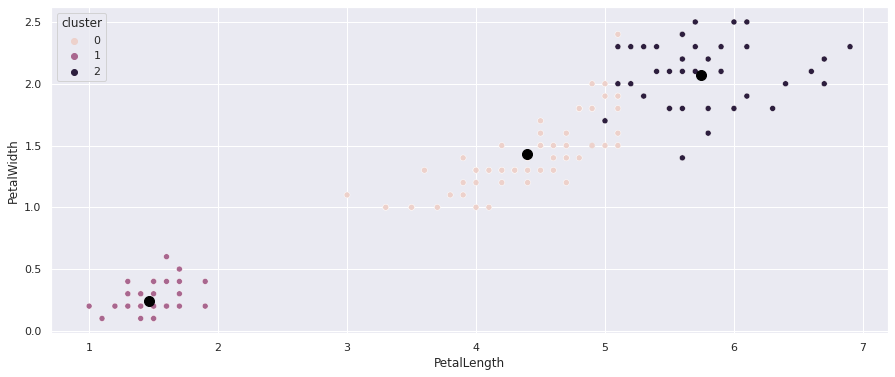
Agora vamos fazer um ScatterPlot usando os rótulos identificados pelo k-Means, assim podemos ver onde estão os centros dos grupos e como o k-Means agrupou esses dados:
1
2
sns.scatterplot(data=df, x='PetalLength', y='PetalWidth', hue='cluster');
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=100, c='black');
Veja como os grupos foram divididos, e no grande grupo que está no centro e no lado superior direito há uma mistura entre os dois grupos identificados que dificulta o agrupamento.
Obs: apesar dos grupos parecerem estar misturados e ter um ponto específico que olhando nesse gráfico parece ser do grupo superior direito, lembre que os dados possuem quatro eixos (características) e neste gráfico estamos visualizando apenas dois eixos.
Fazendo um ScatterPlot, mas agora apresentando os dados de altura e comprimento da sépala, e usando o rótulo gerado pelo k-Means:
1
2
sns.scatterplot(data=df, x='SepalLength', y='SepalWidth', hue='cluster');
plt.scatter(kmeans.cluster_centers_[:, 2], kmeans.cluster_centers_[:, 3], s=100, c='black');
Ainda vemos uma parte dos dados misturados, mas novamente lembre que só estamos visualizando apenas dois dos quatro eixos:
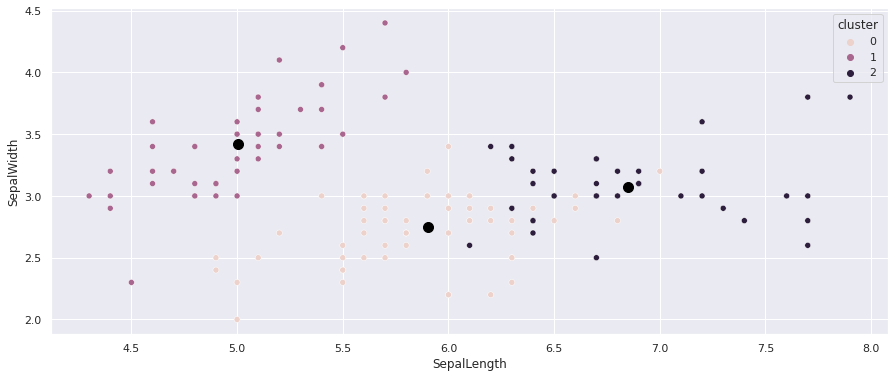
O k-Means oferece uma métrica chamada inertia que mostra uma média do quadrado da distância entre as amostras do grupo:
1
print("Soma do quadrado da distância entre as amostras e seu centro mais próximo: {}".format(kmeans.inertia_))
Neste exemplo temos como resultado:
1
Soma do quadrado da distância entre as amostras e seu centro mais próximo: 78.940841426146
Também podemos olhar os rótulos gerados para cada amostra:
1
print(kmeans.labels_)
Temos como resultado:
1
2
3
4
5
6
7
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 2, 0, 2, 2, 2, 2, 0, 2, 2, 2,
2, 2, 2, 0, 0, 2, 2, 2, 2, 0, 2, 0, 2, 0, 2, 2, 0, 0, 2, 2, 2, 2,
2, 0, 2, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 2, 0, 2, 2, 0], dtype=int32)
Método do cotovelo
Mas e se não sabemos qual a quantidade de grupos queremos? Uma forma simples de identificar a quantidade de grupos que podemos obter é usando o Método do Cotovelo, basicamente treinamos o k-Means com vários k e olhamos o valor da inertia obtida em cada um dos treinos. No exemplo a seguir vou treinar o k-Means com valores de k entre 1 e 20:
1
2
3
4
5
6
distancias = {}
for k in range(1, 21):
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
distancias[k] = kmeans.inertia_
Se fizermos um gráfico simples de linha teremos um desenho similar a um cotovelo:
1
2
sns.pointplot(x = list(distancias.keys()), y = list(distancias.values()))
plt.show();
Quando chegamos em um valor de inertia que começa a reduzir pouco, é um sinal que chegamos na quantidade de grupos sugerida pelos dados:
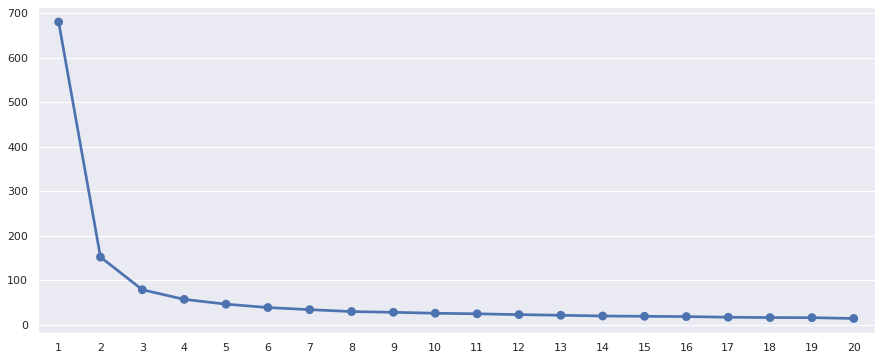
Note no gráfico do cotovelo, como utilizando os dados de Flores Iris, a diferença da inertia entre o k = 3 e o k = 4 é pequena e depois disso temos um decréscimo pequeno, aqui os dados estão sugerindo que há três grupos.
Mais informações e exemplos sobre o k-Means podem ser encontrados no site do Scikit-Learn.