Introdução a classificação de textos

Tudo pode ser classificado e rotulado, mas porque queremos classificar textos ou como isso poderia ajudar o negócio da empresa que trabalho? Temos diversos tipos de textos que podem ser classificados, como: um comentário sobre o produto da empresa; a descrição de um problema que é informado durante um diálogo com o chatbot; o log gerado por uma máquina; dado uma notícia ou artigo definir um ou mais público alvo; entre outros.
Classificar é definir uma ou mais classes (também chamado de rótulos) para algo, no caso de textos podemos identificar se um comentário é positivo, negativo, neutro, agressivo ou sarcástico, por meio de uma análise de sentimentos; a partir da descrição de um chamado podemos redirecionar automaticamente esse chamado para uma área ou grupo de pessoas que conhecem o assunto descrito e podem realizar o atendimento; entre diversos outros usos de texto.
Pense no seu dia a dia, tem algo que você lê e toma uma decisão? Exemplo: leio um comentário de um produto que tenho interesse e decido se vou comprar, leio o resumo de um livro e decido qual seu assunto ou se achei interessante, entre outros.
A partir dos textos, podemos identificar pontos de automatização de processos que facilitariam o dia a dia das pessoas e que também ajudam a economizar custos que demandam muito tempo para analisar os textos. Por exemplo: a partir dos comentários sobre um produto, é possível identificar possíveis problemas, quando identificados grandes quantidades de reclamações similares; ou comentários feitos em uma avaliação institucional ou por meio de redes sociais para identificar possíveis reclamações e pontos de melhorias.
O objetivo desta sequência de posts é ajudar você a implementar um programa capaz de aprender como classificar textos e conseguir implantar esse modelo para que consiga na prática ajudar a sua empresa a automatizar tarefas e economizar (tempo, dinheiro e mão de obra) com isso.
Mas porque você deveria automatizar um processo que faz parte das funções do seu dia a dia? Por experiência própria, não gosto de fazer a mesma coisa várias vezes seguidas, sem ver um fim logo, imagine ter que ficar lendo todos os dias comentários (aqui os comentários podem estar publicados em qualquer meio digital como uma rede social, um comentário no seu próprio site ou em um site de reclamação) sobre os produtos ou serviços que sua empresa possui, e assim identificar se está atendendo bem ou não seus clientes, quanto tempo demoraria para você identificar e melhorar algo?
Mas o que você precisa para criar um modelo de classificação para automatizar esse processo?
Um exemplo que apliquei na prática o uso de classificações de texto foi relacionado com pareceres jurídicos, com base no parecer que o juiz fornece sobre um determinado processo, o modelo treinado realizava a classificação e informava para o advogado qual a próxima etapa desse processo. Essa classificação inicialmente era feita de forma manual, então havia advogados que faziam a leitura dos pareceres para avisar o que foi sentenciado e qual a próxima ação do advogado responsável. Após a implantação do sistema de classificação ocorreram duas mudanças rápidas e significativas para a empresa, primeiro não precisava mais dessas pessoas para ler e dizer o que deveria ser feito, o próprio sistema já informava para o advogado qual a próxima ação que ele deveria tomar, então houve uma mudança nas funções dessas pessoas e elas receberam novas atribuições que possuíam uma importância maior dentro da empresa, segundo ponto de melhoria está relacionada aos prazos, o parecer após classificado automaticamente era rapidamente redirecionado para o advogado, isso ajudou a empresa a reduzir o tempo do andamento dos processos por parte dos advogados.
Mas você deve estar se perguntando que mágica foi essa? Como a partir dos textos foram definidas as suas categorias? Como automatizar esse processo?
É isso que quero mostrar nos próximos posts, feito passo a passo e com pontos que você pode mensurar conforme for fazendo.
Na Figura 1 temos um exemplo de pipeline para criar um classificador de textos composto pelas seguintes fases: adquirir os exemplos de dados que serão usados para treinar o modelo; limpeza dos dados (pré processamento); conversão dos textos para um formato que pode ser usado no treinamento e avaliação do modelo; separar os dados que serão usados no treino e no teste do modelo; treinamento do modelo (aqui temos vários modelos diferentes para escolher), avaliação do modelo treinado (quão bom esse modelo poderá ser quando colocado em produção); disponibilizar o modelo treinado em produção.
Figura 1: Pipeline para criar um classificador de textos.
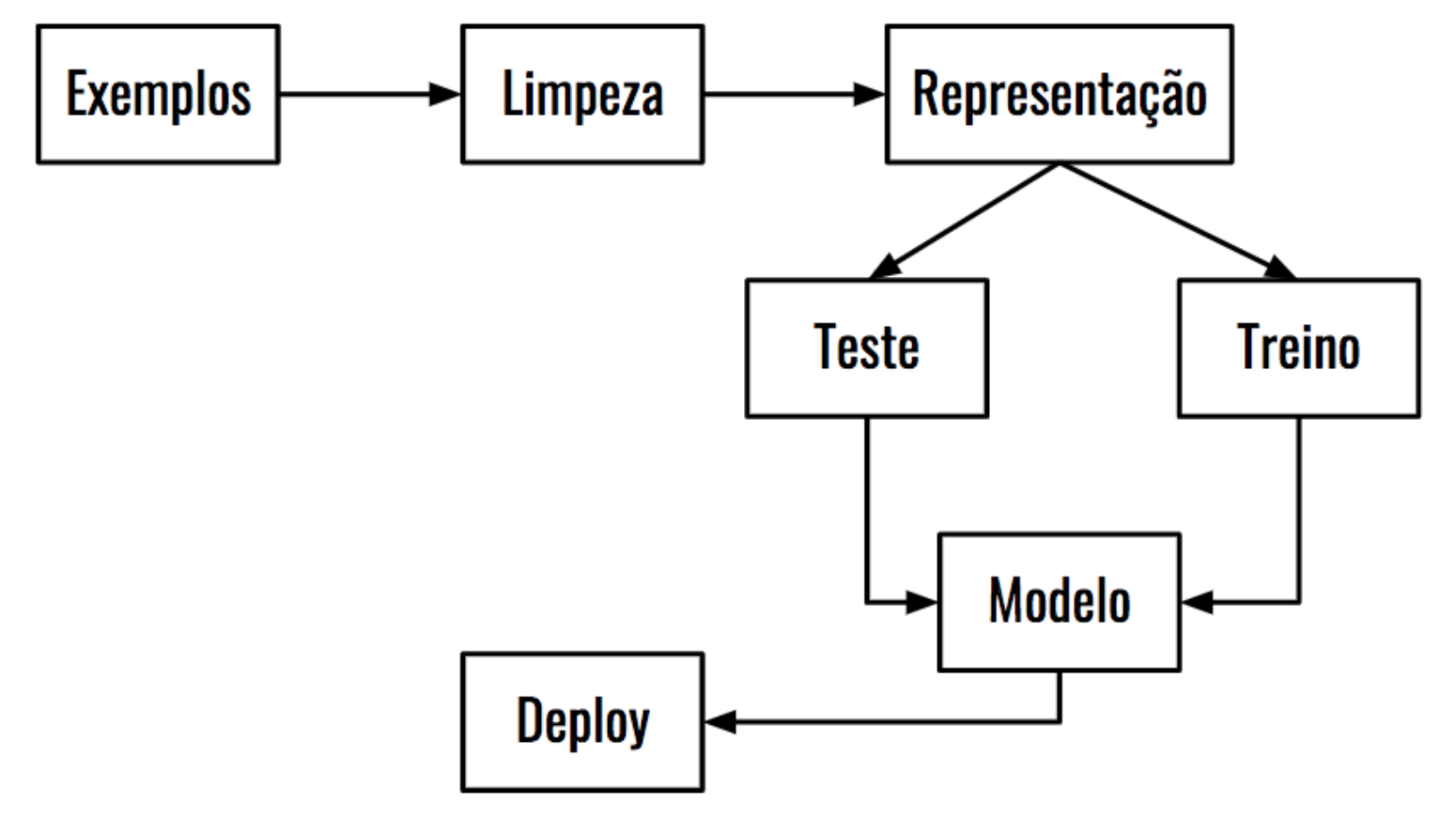
Esse pipeline mostra como treinamos um modelo, que é gerado como resultado ao aplicar um algoritmo de aprendizado de máquinas que utiliza os dados para aprender padrões que identificam como podem ser classificados. Aqui deixo em aberto o tipo do modelo, porque temos diversos modelos (Decision Tree, Random Forest, KNN, SVM, Neural Network, GXBoost, entre outros que podem ser aplicados na tarefa de classificação e veremos alguns deles e suas diferenças. Esse treinamento serve para que o modelo conheça os tipos de textos e suas classificações. Após realizar o treinamento podemos disponibilizar esse modelo para receber novos textos que serão classificados de acordo com o que o modelo aprendeu.
Essa é a introdução, no próximo post vou abordar como montar seu conjunto de dados, que no caso de textos chamamos de corpus.