Implementando uma classificação binária com Regressão Logística

A Regressão Logística internamente calcula o valor da regressão e passa esse valor por uma função logística, no qual dado o valor de entrada, teremos como resultado um valor de saída entre 0 e 1. Então dado a predição feita pela regressão, se o valor predito for maior ou igual a 0.5, temos como saída uma classe positiva, ou o valor 1, mas caso o valor predito for menor que 0.5, então temos como saída uma classe negativa, ou o valor 0.
Como temos como saída as classes positiva e negativa, ou 1 e 0, podemos usar este resultado para fazer uma classificação, se um dado pertence a uma dessas duas classes, e chamamos essa tarefa de Classificação Binária.
Neste exemplo vamos utilizar a Regressão Logística para classificar um conjunto de dados de mensagens de SMS entre SPAM ou NÃO SPAM. Vamos utilizar o Dataset SMS Spam que possui as mensagens de SMS e já foi classificado como spam ou ham (não spam).
Se quiser conhecer a história do porque o nome é SPAM dá uma olhada neste link
Vamos começar lendo o arquivo SMSSpamCollection com o Pandas:
1
2
3
4
5
import pandas as pd
atributos = ['classe', 'mensagem']
df_sms = pd.read_csv('SMSSpamCollection', delimiter='\t', header=None, names=atributos)
df_sms.head()
Vejamos alguns exemplos deste dataset:
Vamos separar o dataset em duas partes, um DataFrame sms com os textos das mensagens e um DataFrame classe com as classificações de cada mensagem.
1
2
3
sms = df_sms['mensagem'].values
classe = df_sms['classe'].values
print(sms)
No DataFrame de sms teremos uma mensagem para cada linha:
1
2
3
4
5
6
['Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...'
'Ok lar... Joking wif u oni...'
"Free entry in 2 a wkly comp to win FA Cup final tkts 21st May 2005. Text FA to 87121 to receive entry question(std txt rate)T&C's apply 08452810075over18's"
... 'Pity, * was in mood for that. So...any other suggestions?'
"The guy did some bitching but I acted like i'd be interested in buying something else next week and he gave it to us for free"
'Rofl. Its true to its name']
Vamos imprimir também o DataFrame das classes:
1
print(classe)
Temos duas classes ham ou spam e como vamos gerar um classificador para essas duas classes, chamamos isso de Classificação Binária:
1
['ham' 'ham' 'spam' ... 'ham' 'ham' 'ham']
Convertendo os textos para representações numéricas
Primeiro ponto interessante é que vamos trabalhar com textos, tanto das mensagens dos SMS, como das classes, então vamos converter esses textos para features numéricas.
Existem diversas formas de converter textos em features numéricas, podemos fazer binarização, contagem de palavras, TF (frequência dos termos), TF/IDF, entre outros, neste exemplo vou usar o TF/IDF.
A ideia do TF/IDF é que as frequência das palavras tem uma relevância dentro do texto e podem ajudar a identificar as principais palavras que identificam um texto, no caso do TF/IDF as palavras que mais aparecem muitas vezes são as menos relevantes, então é dado um peso maior em consideração as palavras que menos aparecem porque elas podem indicar o assunto principal que o texto está tratando.
No Scikit-Learn temos uma classe que nos ajuda a fazer a geração do TF/IDF, é a TfidfVectorizer
No TfidfVectorizer passamos para ele o DataFrame de textos e ele gera um novo DataFrame como resultado, também podemos passar um padrão que ele deve aplicar nos dados, nesse exemplo vou informar no padrão que deve usar apenas palavras que possuem caracteres de a até z e também apenas palavras com pelo menos 3 caracteres.
O TfidfVextorizer aceita vários outros parâmetros como o tipo de encoding dos textos, uma lista de palavras para ignorar (stop words), se deve remover os acentos, entre outros, dê uma olhada na documentação para conhecer os demais parâmetros.
1
2
3
4
5
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(token_pattern=u'[a-zA-Z]{3,}')
tfidf.fit(sms)
sms_vector = tfidf.transform(sms)
Após chamar a função transform ganhamos algumas coisas, temos um vocabulário que foi gerado com base em todas as palavras distintas encontradas nos textos dos SMSs, para cada palavra temos um número que representa o índice desta palavra, vejamos as primeiras 100 palavras encontradas:
1
2
for key in sorted(tfidf.vocabulary_.keys())[:100]:
print("{}: {}".format(key, tfidf.vocabulary_[key]))
Aqui mostro apenas as primeiras 10 palavras para não ficar muito grande:
1
2
3
4
5
6
7
8
9
10
aah: 0
aaniye: 1
aaooooright: 2
aathi: 3
abbey: 4
abdomen: 5
abeg: 6
abel: 7
aberdeen: 8
abi: 9
Agora vamos dar uma olhada na transformação que vamos fazer nos textos dos SMSs, primeiro vamos ver como é um texto de um SMS:
1
print('SMS original: {}'.format(sms[0]))
1
SMS original: Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat…
Quando transformamos o texto com o TF/IDF temos um vetor que representa os pesos que foram atribuídos a cada palavra que aparece no SMS:
1
print('SMS tfidf value: {}'.format(sms_vector[0]))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
SMS tfidf value:
(0, 7325) 0.23401469690389942
(0, 7107) 0.19330107790224554
(0, 6891) 0.24374816538134755
(0, 6517) 0.16479914313027855
(0, 4827) 0.270593923017957
(0, 4466) 0.16516111063793318
(0, 3355) 0.34595949285545796
(0, 2681) 0.19110821446920698
(0, 2643) 0.16201909870273148
(0, 1413) 0.26792181244961244
(0, 1146) 0.29226797758223916
(0, 866) 0.29226797758223916
(0, 864) 0.33025573133459285
(0, 448) 0.25876641800827593
(0, 217) 0.34595949285545796
A partir do vetor gerado pelo TF/IDF podemos inverter a transformação e olhar quais foram as palavras usadas para representar o vetor do SMS:
1
print('SMS vector: {}'.format(tfidf.inverse_transform(sms_vector[0])))
Note como o padrão que definimos no TF/IDF foi aplicado, só temos palavras com 3 ou mais caracteres e que contém apenas caracteres entre a e z.
1
2
3
SMS vector: [array(['world', 'wat', 'until', 'there', 'point', 'only', 'jurong',
'great', 'got', 'crazy', 'cine', 'bugis', 'buffet', 'available',
'amore'], dtype='<U34')]
Agora vamos usar o LabelEncoder para tratar os dois valores que temos para as classes que queremos classificar:
1
2
3
4
5
from sklearn import preprocessing
le = preprocessing.LabelEncoder()
le.fit(classe)
classe_encoder = le.transform(classe)
Quando passamos o DataFrame de classes para o LabelEncoder, temos como resultado um novo DataFrame em que os valores das classes foram convertidos de dados qualitativos para dados quantitativos.
1
print(classe_encoder)
1
[0 0 1 ... 0 0 0]
No LabelEncoder se precisar podemos ver quais os valores encontrados no DataFrame e que foram gerados os encodes:
1
print(le.classes_)
1
['ham' 'spam']
Treinando e avaliando a Regressão Logística
Agora vamos usar o DataFrame sms_vector do sms que foi aplicado o TF/IDF e o DataFrame classe_encoder das classes após aplicar o LabelEncoder e separar cada um deles em dois DataFrames para usarmos como dados de treino e teste do modelo.
1
2
3
4
from sklearn.model_selection import train_test_split
# separa 75% dos dados para treino e 25% para teste.
X_treino, X_teste, y_treino, y_teste = train_test_split(sms_vector, classe_encoder, train_size=0.75)
A ideia de separar os dados em treino e teste é poder treinar a Regressão Logística com uma parte dos dados e depois usar uma parte que o modelo nunca viu para avaliar o seu desempenho.
Os dados de entrada usados no treino do modelo são os textos dos SMSs após aplicar o TF/IDF:
1
print(X_treino)
1
2
3
4
5
6
7
8
9
(0, 7435) 0.19813621918140387
(0, 5970) 0.4047084749261841
(0, 5813) 0.5243424416824478
…
Os dados de saída usado no treino são as classes spam ou ham após aplicar o LabelEncoder:
``` python
print(y_treino)
1
[0 0 0 ... 1 0 1]
Vamos então treinar a Regressão Logística:
1
2
3
4
5
6
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_treino, y_treino)
y_predito = model.predict(X_teste)
Com o modelo treinado, vamos fazer uma validação cruzada, vamos dividir os dados de teste em cinco partes e avaliar o modelo com cada uma dessas partes e depois ver como está a acurácia média do modelo:
1
2
3
from sklearn.model_selection import cross_val_score
scores_dt = cross_val_score(model, X_teste, y_teste, scoring='accuracy', cv=5)
print(scores_dt.mean())
A acurácia de 0.91 indica que a cada 10 SMSs estamos conseguindo classificar corretamente 9, ou a cada 100 SMSs estamos classificando corretamente 91:
1
0.9109847605786339
Vamos dar uma olhada na matriz de confusão.
1
2
3
from sklearn.metrics import confusion_matrix
matrix = confusion_matrix(y_teste, y_predito)
print(matrix)
O legal da Matriz de Confusão é olhar para a matriz diagonal e verificar se os valores estão bem maiores que os demais valores, isso indica que está mais acertando do que errando as classificações de cada uma das classes:
1
2
[[1207 1]
[ 60 125]]
Se preferir pode gerar um gráfico de cores para visualizar os valores da Matriz de Confusão:
1
2
3
from sklearn.metrics import ConfusionMatrixDisplay
disp = ConfusionMatrixDisplay(confusion_matrix=matrix, display_labels=le.classes_)
disp.plot();
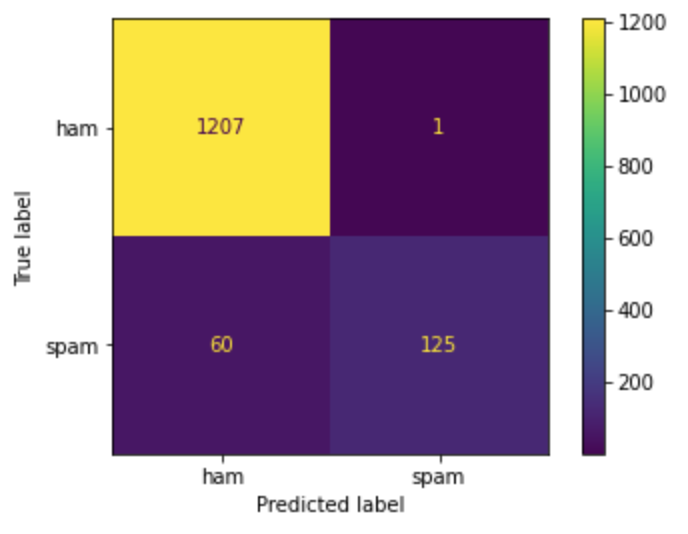
Olhando para a primeira linha da matriz, podemos entender que das 1208 amostras ham (que não são spam), classificou corretamente 1207 e errou apenas 1, isso é bom porque ninguém quer suas mensagens reais sendo classificadas como spam; e para as 185 amostras de spam classificou corretamente 125 e errou 60, isso é aceitável, mas dá margem para melhorar.
O erro na classificação do spam parece ser devido aos dados que possuem muito mais amostras do tipo ham, então o modelo aprendeu melhor como classificar este tipo de dado. Para melhorar o treino, pode aumentar a quantidade de amostras do tipo spam, ou reduzir as amostras do tipo ham, ou analisar os registros classificados incorretamente para tentar encontrar um padrão no comportamento e entender quais palavras estão mais associadas a ham e quais palavras estão mais associadas a spam, só cuidado para não começar a classificar como spam muitos registros que são do tipo ham.