Regressão Linear no Spark com MLLib

A Regressão Linear é usada quando queremos predizer um valor e para isso usamos um conjunto de dados conhecido para treinar esse modelo. Caso queira conhecer um pouco mais, nestes posts comento sobre o treinamento da Regressão Linear Simples e Múltipla.
A Figura 1 mostra um exemplo de gráfico de linhas que compara o valor real e o valor predito por uma Regressão Linear Simples:
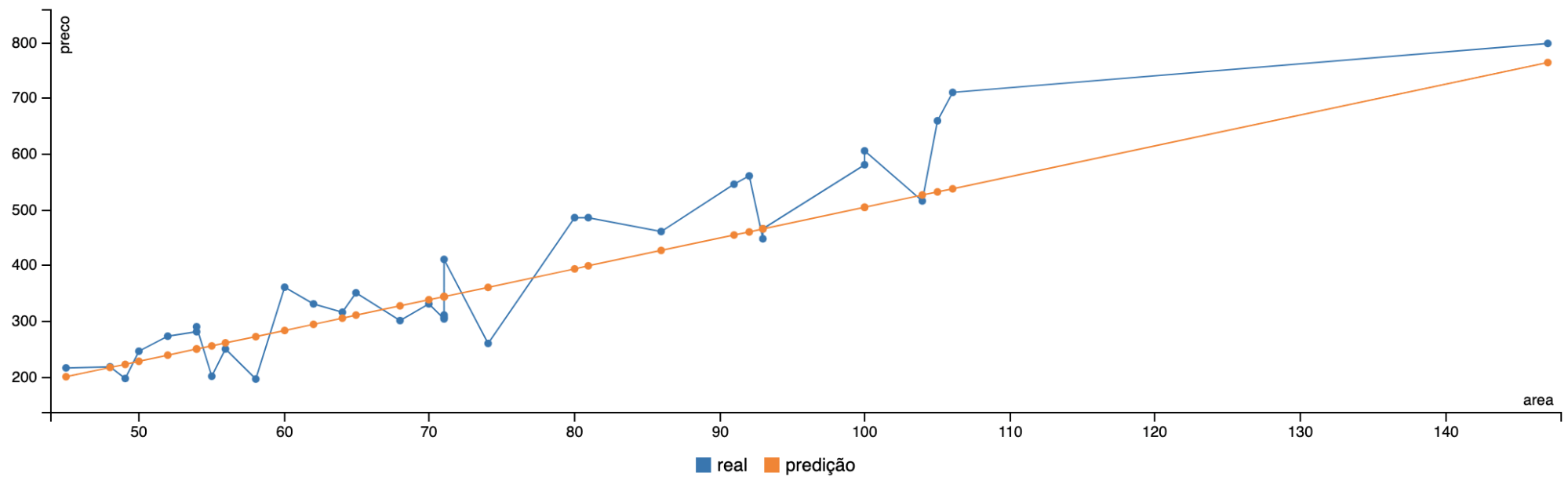
A ideia deste post é mostrar como treinar um modelo de Regressão Linear no Apache Spark usando dados que estão armazenados no HDSF, assim tanto o armazenamento como o processamento dos dados serão feitos de forma distribuída.
O código do post será escrito em Scala, lembrando que o Spark suporta também Java e Python, então o importante é entender o conceito e não ficar preso a linguagem de programação usada nos exemplos.
Vou usar um conjunto de dados com algumas informações sobre 100 apartamentos de SBC que coletei aleatoriamente e coloquei nesse csv. O arquivo aptos-metro-valor.csv foi salvo no diretório /datasets dentro do HDFS.
Neste exemplo vamos:
- Implementar o código Spark que lê os dados guardados no HDFS;
- Separar o dataset em treino e teste;
- Treinar um modelo de Regressão Linear Simples e Múltipla usando o dataset de treino;
- Usar o modelo treinado para predizer os valores do dataset de teste;
- Avaliar o modelo com Validação Cruzada;
- Guardar o resultado da predição em um arquivo.
Conectando no Spark e lendo os dados no HDFS
Você pode criar um programa que envie este código para ser processado no Apache Spark ou usar o [Spark Notebook] (https://github.com/spark-notebook/spark-notebook) para executar interativamente este código. Vamos começar criando uma conexão com o Spark:
1
2
3
4
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types._
val spark = SparkSession.builder().appName("Exemplo de Regressão Linear").getOrCreate()
Quando queremos ler um arquivo e gerar um DataFrame, temos a opção de deixar o Spark inferir ou informar um esquema que define os tipos de dados de cada coluna do arquivo. Nesse exemplo vou montar um esquema para informar as colunas e tipos de dados do arquivo CSV:
1
2
3
4
5
6
7
8
9
val schema = StructType(Array(
StructField("area", DoubleType, true),
StructField("preco", DoubleType, true),
StructField("quartos", IntegerType, true),
StructField("vagas", IntegerType, true),
StructField("reformado", IntegerType, true),
StructField("bairro", StringType, true)
)
)
O Apache Spark suporta vários formatos de arquivos que contém os dados que serão carregados no DataFrame. O trecho de código a seguir lê o arquivo no formato CSV, informa que este arquivo possui cabeçalho (a primeira linha tem os nomes das colunas) e pede para o Spark aplicar o esquema das colunas definido no passo anterior.
Obs: na leitura de um arquivo CSV também podemos informar o tipo de separador das colunas, aqui não usei porque no CSV usado no exemplo já estou usando a separação default das colunas que é vírgula.
1
2
val df = spark.read.schema(schema).option("header","true")
.csv("hdfs://namenode:9000/datasets/aptos.csv").toDF
Foi criado um DataFrame chamado df, vamos dar uma olhada e ver como ficou o esquema usando o método printSchema() e as primeiras linhas que foram carregadas usando o método show() do DataFrame:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
df.printSchema()
root
|-- area: double (nullable = true)
|-- preco: double (nullable = true)
|-- quartos: integer (nullable = true)
|-- vagas: integer (nullable = true)
|-- reformado: integer (nullable = true)
|-- bairro: string (nullable = true)
df.show()
+-----+-----+-------+-----+---------+--------------+
| area|preco|quartos|vagas|reformado| bairro|
+-----+-----+-------+-----+---------+--------------+
|107.0|560.0| 3| 2| 0|Vila Lusitania|
|107.0|555.0| 3| 2| 1|Vila Lusitania|
| 49.0|196.0| 2| 1| 0| Ferrazopolis|
|104.0|515.0| 3| 2| 1| Centro|
| 92.0|560.0| 3| 2| 1|Vila Lusitania|
...
+-----+-----+-------+-----+---------+--------------+
Observação: os gráficos gerados servem para entender melhor os dados, utilizei a biblioteca de gráficos do Spark Notebook, estou colocando os códigos de como gerar os gráficos para caso você também queira reproduzir.
A partir deste DataFrame, podemos fazer algumas explorações, vejamos no gráfico de dispersão (Figura 2) a relação entre os valores da área e preço dos apartamentos.
1
ScatterChart(df, fields=Some("area", "preco"))
Figura 2: Gráfico de dispersão entre o valor do preço e a área dos apartamentos.
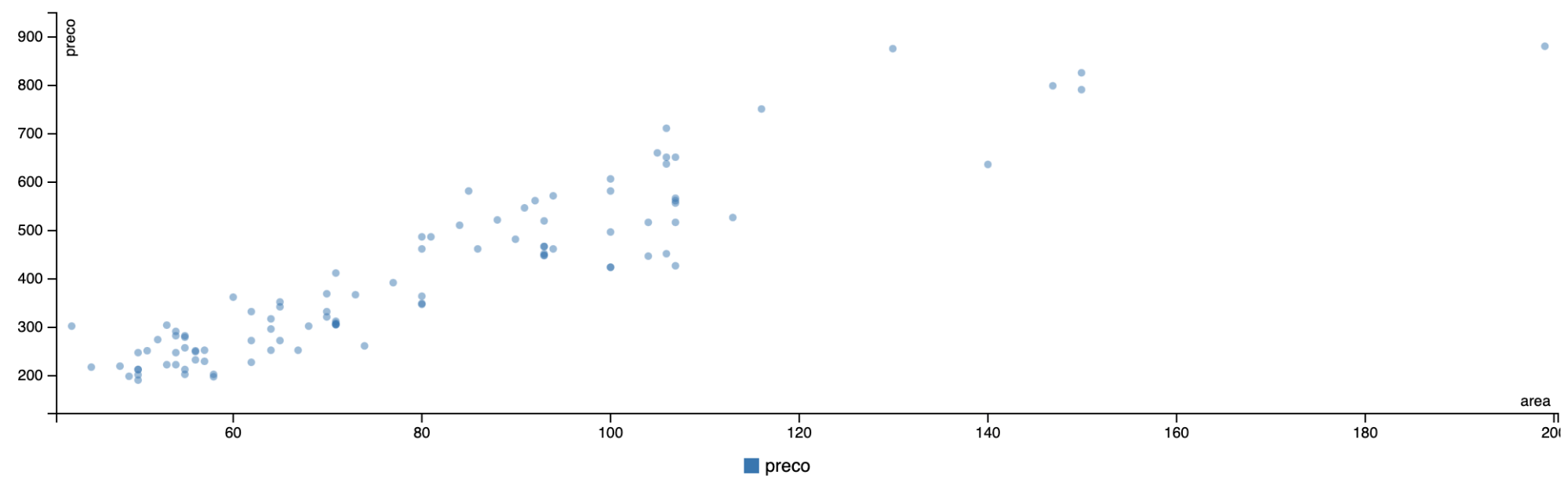
Após ler os dados e montar o DataFrame, o próximo passo é preparar os dados para realizar o treino da Regressão Linear.
Treinando uma Regressão Linear Simples no Spark
O Apache Spark possui diversas bibliotecas para serem utilizadas nos pipelines, sendo uma delas a biblioteca de aprendizado de máquinas chamada MLlib.
O MLlib possui implementação de diversos modelos de classificação e regressão, agrupamento, funções para selecionar, extrair ou transformar as features, entre outros, que podem ser utilizadas no treinamento dos modelos.
O primeiro passo para treinar uma Regressão Linear, é escolher quais serão as features (características disponíveis ou geradas a partir dos dados), neste primeiro exemplo vou utilizar apenas o valor da area dos apartamentos para tentar predizer o valor do preço do apartamento.
Vou usar a função de transformação chamada VectorAssembler que serve para unir diversas features que serão usadas no treinamento do modelo em um único vetor. O VectorAssembler vai receber como entrada (input cols) um arrays com os nomes das colunas e como saída (output col) o nome da coluna que ele vai gerar.
1
2
3
val assembler = new VectorAssembler()
.setInputCols(Array("area"))
.setOutputCol("features")
Vou aplicar este VectorAssembler que chamei apenas de assembler no DataFrame df, mas selecionando apenas as colunas area e preco. Como resultado teremos um novo DataFrame que chamei de df_assembler, contendo as colunas area, preco e features.
Note que a coluna features é um vetor contendo apenas o valor da coluna area, no próximo exemplo vamos criar um vetor com mais features.
1
2
3
4
5
6
7
8
9
10
11
12
13
val df_assembler = assembler.transform(df.select("area", "preco"))
df_assembler.show()
+-----+-----+--------+
| area|preco|features|
+-----+-----+--------+
|107.0|560.0| [107.0]|
|107.0|555.0| [107.0]|
| 49.0|196.0| [49.0]|
|104.0|515.0| [104.0]|
| 92.0|560.0| [92.0]|
...
+-----+-----+--------+
Após a criação da coluna de features, vamos separar o DataFrame em duas partes, uma parte será usada no treino e a outra parte no teste. Vou separar o DataFrame de modo aleatório, sendo 70% dos dados para treino e 30% dos dados para teste, mas existem diversas outras formas de separar as amostras de treino e teste.
1
2
3
val splits = df_assembler.randomSplit(Array(0.7, 0.3))
val training = splits(0)
val test = splits(1)
Agora vamos realizar o treino do modelo de Regressão Linear. Comece importando a classe LinearRegression e criando um objeto com as configurações de treino. Aqui estou usando uma configuração básica dos hiperparâmetros para treinar o modelo, sendo no máximo 10 iterações, usando os valores 0.3 para o regParam e 0.8 para ElasticNet como medida para a regularização, e a coluna com os valores reais que o modelo deve usar para aprender estão na coluna preco.
1
2
3
4
5
6
7
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
.setLabelCol("preco")
O LinearRegression possui o método fit que serve para treinar o modelo com base nos dados disponíveis no DataFrame, aqui vou usar o dataset de treino. E aqui o Spark faz o processo de treino do modelo de modo distribuído.
1
val model = lr.fit(training)
Com o modelo treinado vamos utilizar o DataFrame de teste para avaliar a predição feita pelo modelo e ver alguns valores do resultado.
1
2
val df_prediction = model.transform(test)
df_prediction.show()
O DataFrame df_prediction vai ganhar uma coluna nova chamada prediction contendo o valor que o modelo prediz para o preço do apartamento com base no tamanho da área.
1
2
3
4
5
6
7
8
9
10
+----+-----+--------+------------------+
|area|preco|features| prediction|
+----+-----+--------+------------------+
|45.0|215.0| [45.0]|199.17889945545826|
|48.0|217.0| [48.0]|215.78183652067293|
|49.0|196.0| [49.0]| 221.3161488757445|
|50.0|245.0| [50.0]|226.85046123081605|
|52.0|272.0| [52.0]|237.91908594095918|
...
+----+-----+--------+------------------+
Na Figura 3 temos um gráfico de linha que compara o valor do preço real com o valor que foi predito pelo modelo.
Figura 3: Comparação entre o valor real e o valor predito pelo modelo.
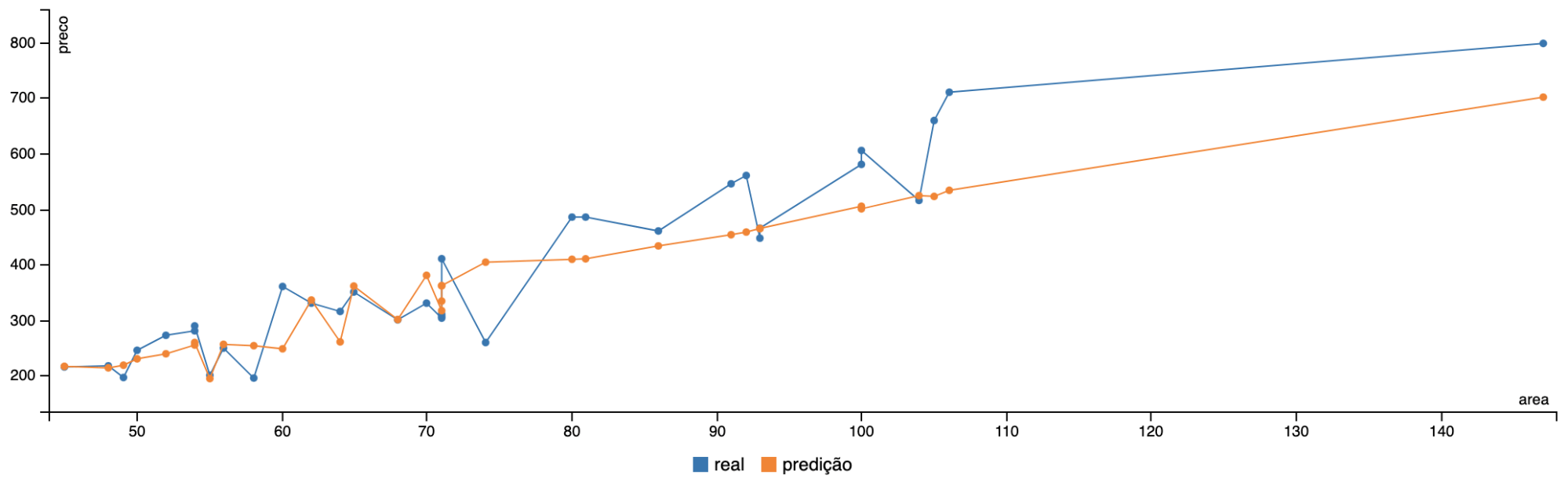
Daqui a pouco vamos avaliar se o modelo treinado ficou bom ou não, por enquanto podemos perceber com o modelo da Regressão Linear gera valores que seguem a tendência dos dados.
Agora vamos adicionar mais algumas features e fazer o treino de uma Regressão Linear Múltipla.
Treinando uma Regressão Linear Múltipla no Spark
No DataFrame temos diversas colunas que podem ajudar a predizer melhor o valor de um apartamento. A coluna bairro do tipo String precisa de um pré-processamento, porque não podemos usar uma coluna do tipo String na Regressão Linear, então primeiro precisamos converter sua informação para um tipo numérico.
Existem várias formas de converter texto (string) em número, uma delas é usando o StringIndexer que usa as strings únicas da coluna, ordena essas strings em ordem alfabética e gera um número sequencial para cada uma, depois gera uma nova coluna contendo o valor que foi atribuído a cada string.
1
2
3
4
5
6
7
8
import org.apache.spark.ml.feature.StringIndexer
val bairroIndexer = new StringIndexer()
.setInputCol("bairro")
.setOutputCol("bairroIndex")
val df_indexed = bairroIndexer.fit(df).transform(df)
df_indexed.show()
Quando criamos um StringIndexer, informamos a coluna de entrada e a nova coluna que será gerada. Aplicando o StringIndexer no df geramos um novo DataFrame com a nova coluna bairroIndex:
1
2
3
4
5
6
7
8
9
10
+-----+-----+-------+-----+---------+--------------+-----------+
| area|preco|quartos|vagas|reformado| bairro|bairroIndex|
+-----+-----+-------+-----+---------+--------------+-----------+
|107.0|560.0| 3| 2| 0|Vila Lusitania| 4.0|
|107.0|555.0| 3| 2| 1|Vila Lusitania| 4.0|
| 49.0|196.0| 2| 1| 0| Ferrazopolis| 8.0|
|104.0|515.0| 3| 2| 1| Centro| 0.0|
| 92.0|560.0| 3| 2| 1|Vila Lusitania| 4.0|
...
+-----+-----+-------+-----+---------+--------------+-----------+
Agora vamos usar o VectorAssembler selecionando as colunas area e preco, quartos, vagas, reformado e bairroIndex.
1
2
3
4
5
val assembler = new VectorAssembler()
.setInputCols(Array("area","quartos","vagas","reformado","bairroIndex"))
.setOutputCol("features")
val df_assembler = assembler.transform(df_indexed).select("area", "preco","quartos","vagas","reformado", "bairroIndex", "features")
df_assembler.show()
Como resultado teremos um novo DataFrame contendo as colunas area e preco, quartos, vagas, reformado, bairroIndex e features.
1
2
3
4
5
6
7
8
9
10
+-----+-----+-------+-----+---------+-----------+--------------------+
| area|preco|quartos|vagas|reformado|bairroIndex| features|
+-----+-----+-------+-----+---------+-----------+--------------------+
|107.0|560.0| 3| 2| 0| 4.0|[107.0,3.0,2.0,0....|
|107.0|555.0| 3| 2| 1| 4.0|[107.0,3.0,2.0,1....|
| 49.0|196.0| 2| 1| 0| 8.0|[49.0,2.0,1.0,0.0...|
|104.0|515.0| 3| 2| 1| 0.0|[104.0,3.0,2.0,1....|
| 92.0|560.0| 3| 2| 1| 4.0|[92.0,3.0,2.0,1.0...|
...
+-----+-----+-------+-----+---------+-----------+--------------------+
Vamos novamente separar o dataset em treino e teste, respectivamente 70% e 30%:
1
2
3
val splits = df_assembler.randomSplit(Array(0.7, 0.3))
val training = splits(0)
val test = splits(1)
E vamos retreinar o modelo de Regressão Linear:
1
val model = lr.fit(training)
O novo modelo de Regressão Linear será treinado usando agora mais features sobre os apartamentos. Com este modelo treinado podemos fazer a predição dos dados de teste:
1
2
3
val predicao = model.transform(test)
predicao.show()
Como resultado temos um novo DataFrame chamado predicao com a nova coluna prediction que contém os valores predito pela Regressão Linear:
1
2
3
4
5
6
7
8
9
10
+----+-----+-------+-----+---------+-----------+--------------------+------------------+
|area|preco|quartos|vagas|reformado|bairroIndex| features| prediction|
+----+-----+-------+-----+---------+-----------+--------------------+------------------+
|45.0|215.0| 2| 1| 1| 2.0|[45.0,2.0,1.0,1.0...|216.05851244370365|
|48.0|217.0| 2| 1| 0| 8.0|[48.0,2.0,1.0,0.0...| 213.3625333848461|
|49.0|196.0| 2| 1| 0| 8.0|[49.0,2.0,1.0,0.0...|218.14164863150677|
|50.0|245.0| 2| 1| 1| 7.0|[50.0,2.0,1.0,1.0...|229.59115512969237|
|52.0|272.0| 2| 1| 0| 5.0|[52.0,2.0,1.0,0.0...|238.69675449987758|
...
+----+-----+-------+-----+---------+------==---+--------------------+------------------+
Na Figura 4 temos um gráfico de linha que compara o valor do preço real com o valor que foi predito pelo modelo, note que apesar de linear, agora não temos mais uma linha contínua, temos variação por conta das diversas características usadas no treino.
Figura 4: Comparação entre o valor real e o valor predito pelo modelo.
Avaliando o modelo treinado
Vamos avaliar o modelo usando uma Validação Cruzada, cada tipo de modelo possui algumas métricas específicas para avaliá-lo, vamos usar duas métricas simples para regressão que são calculadas sobre o erro médio.
Usando a Regressão Linear:
1
2
3
4
5
6
7
import org.apache.spark.ml.regression.LinearRegression
val lr = new LinearRegression()
.setMaxIter(10)
.setRegParam(0.3)
.setElasticNetParam(0.8)
.setLabelCol("preco")
Vamos criar um Pipeline que é uma sequência de passos para o treino do modelo. No pipeline definimos no stages um array de estágios de processamento que representam os passos que serão executados neste pipeline, aqui vamos só usar o modelo da Regressão Linear, mas podemos encadear uma sequência de operações:
1
2
import org.apache.spark.ml.Pipeline
val pipeline = new Pipeline().setStages(Array(lr))
O RegressionEvaluator permite escolher a métrica que será coletada durante o treino do modelo. A seguir será configurado para coletar a métrica de Raiz do Erro Médio Quadrático (RMSE).
Obs: no metricName podemos escolher entre as métricas: rmse - Raiz do Erro Médio Quadrático, mse - Erro Médio Quadrático, r2 - R² (coeficiente de determinação, mae - Erro Médio Absoluto e var - Variância.
1
2
import org.apache.spark.ml.evaluation.RegressionEvaluator
val evaluator = new RegressionEvaluator().setMetricName("rmse").setPredictionCol("preco").setLabelCol("preco")
A seguir criamos um ParamGrid que servirá para encontrar qual o melhor valor para o parâmetro de regularização da Regressão Linear (isso serve para restringir os pesos do modelo para evitar overfitting), sendo que para cada modelo treinado utilizará no regParam (parâmetro de regularização) um dos valores 0, 0.5 e 1 para ver qual destes valores gerará um modelo com melhor resultado.
1
2
import org.apache.spark.ml.tuning.ParamGridBuilder
val params = new ParamGridBuilder().addGrid(lr.regParam, Array(0, 0.5, 1)).build()
Então criamos o CrossValidator (validação cruzada) que vai treinar e avaliar como o modelo está aprendendo durante o seu treino. A ideia da Validação Cruzada é separar de modo aleatório o conjunto de dados de treino em folds (partes) de tamanho igual e a cada iteração do treino uma dessas partes fica escondida e as demais são usadas para treinar o modelo, esta parte escondida será usada para avaliar o treino do modelo.
A seguir estou passando para a validação o pipeline, evaluator, params e definindo que deve fazer a validação cruzada com cinco folds.
1
2
import org.apache.spark.ml.tuning.CrossValidator
val cv = new CrossValidator().setEstimator(pipeline).setEvaluator(evaluator).setEstimatorParamMaps(params).setNumFolds(5)
Neste exemplo a validação cruzada vai treinar o modelo cinco vezes, e durante cada treino vai usar combinações diferentes para selecionar quatro folds (partes) para o treino e uma fold (parte) para o teste, após os cinco treinos seleciona o melhor modelo:
1
val model_cv = cv.fit(training)
Com o modelo treinado vamos primeiro predizer os dados de teste e depois selecionar apenas as colunas de prediction e preco para calcular algumas métricas:
1
2
3
val out = model_cv.transform(test)
.select("prediction", "preco")
.rdd.map(x => (x(0).asInstanceOf[Double], x(1).asInstanceOf[Double]))
No MLlib cada modelo tem uma classe com um conjunto de métricas que podem ser coletadas, no caso da Regressão vamos usar o RegressionMetrics:
1
2
3
4
5
import org.apache.spark.mllib.evaluation.RegressionMetrics
val metrics = new RegressionMetrics(out)
println("MSE = " + metrics.meanSquaredError)
println("RMSE = " + metrics.rootMeanSquaredError)
A Regressão Linear teve como Erro Médio Quadrática (MSE) e a Raiz do Erro Médio Quadrática (RMSE):
1
2
MSE = 4.621414815680551E10
RMSE = 214974.76167402888
Aqui não vou avaliar se treinamos o melhor modelo para servir de regressão linear, mas a ideia é te mostrar os passos para criar o seu modelo, depois conforme a avaliação dos dados que você for treinando haverá a necessidade de um ajuste fino nos hiperparâmetros.
Após o treino e avaliação do modelo, podemos salvar o modelo em disco para poder usá-lo com novos dados.
1
2
3
model.save(sc, "target/models/linearRegressionModel")
val savedModel = LinearRegressionModel.load(sc, "target/models/linearRegressionModel")
Sugestões: quando você for salvar o modelo de um número de versão a cada novo modelo treinado, assim se precisar voltar uma versão do passado você terá as versões anteriores; sempre guarde uma cópia do pipeline que gerou o modelo (Model Lineage), com o tempo esquecemos as mudanças de cada versão e se você guardar o código que gerou cada versão poderá usar uma ferramenta para comparar e saber exatamente o que mudou de uma versão para outra; saiba a origem dos dados e se esses dados podem ser usados para o propósito do modelo treinado.